Named Entity Recognition (NER) offers a great way to understand a given textual information and identify specific entities or tags within it for various applications.
From categorizing people’s names to pointing dates, organizations, locations, and more, NER makes its own way for a better understanding of language.
Many organizations deal with a large volume of data in the form of content, personal information, customer feedback, product details, and many more.
When you need information instantly, you will need to perform search operations to get the result, which can consume a lot of time, energy, and resources, especially when dealing with large data volumes.
To empower organizations with an effective solution for search operations and finding the right data, NER is an excellent option.
In this article, I’ll discuss NER in detail, its mathematical concept, its different uses, and other important points.
Let’s start!
What Is Named Entity Recognition?
Named Entity Recognition (NER) is a method of Natural Language Processing (NLP) that can identify and classify entities within textual, unstructured data.
These entities contain a wide range of information, such as organizations, locations, names of individuals, numerical values, dates, and more. It empowers machines to extract the above entities, making it a useful tool for applications like translation, answering questions, etc., across several industries.
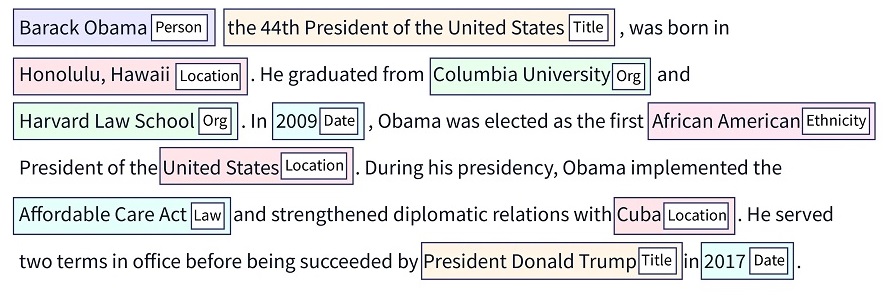
So, NER seeks to locate and categorize the different entities in an unstructured text into predefined groups such as organizations, medical codes, quantities, person names, percentages, monetary values, time expressions, and more.
Let’s understand this with an example:
[William] bought a property from [Z1 Corp.] in [2023]. Here the blocks are the entities identified by NER. They are classified as:
William – Name of a person
Z1 Corp. – Organization
2003 – Time
NER is used in several fields of AI, including deep learning, machine learning (ML), and neural networks. It is a critical component of NLP systems, such as sentiment analysis tools, search engines, and chatbots. In addition, it can be used in finance, customer support, higher education, healthcare, human resources, and social media analysis.
Simply put, NER identifies, classifies, and extracts the essential information from the unstructured text without any human analysis. It can extract key information quickly from the available set of large data.
Furthermore, NER delivers essential insights to your organization about the products, market trends, customers, and competition. For example, healthcare Institutions use NER to extract essential medical data from patient records. Many companies use it to identify whether they are mentioned in any publications.
Key Concepts: NER

It is important to know the basic concepts involved in NER. Let’s discuss some key terms related to NER to be familiar with.
- Named Entity: Any word that refers to a place, organization, person, or other entity.
- Corpus: A collection of different texts used to analyze languages and train NER models.
- POS tagging: A process where the text is labeled according to corresponding speech, such as adjectives, verbs, and nouns.
- Chunking: It is a process used to group words into different meaningful phrases based on the syntactic structure and part of speech.
- Training and testing data: This is the process used to train a model with labeled data and evaluate the performance of the first set on another set of data.
Use of NER in NLP

NER has multiple applications in NLP, such as sentiment analysis, recommendation systems, question-answering, information extraction, and more.
- Sentiment analysis: NER is used to detect the sentiment expressed in a sentence or para towards a specific named Entity, like a product or service. This data is used to enhance customer experience and identify the improvement areas.
- Recommendation systems: NER is used to identify the preferences and interests of users based on the named entities mentioned in the online interactions or search queries. This data is used to enhance user improvement by providing personalized recommendations.
- Question answering: NER is used to detect certain entities from a text, which is further used to answer a query or specific question. This is generally used for virtual assistants and chatbots.
- Information extraction: NER is used to extract essential information from a larger set of unstructured text. This includes social media posts, online reviews, news articles, and more. This data is used to generate valuable insights and make data-driven decisions.
Mathematical Concepts: NER
The NER process includes different mathematical concepts, such as machine learning, deep learning, probability theory, and more. Here are some mathematical techniques:
- Hidden Markov Models: Hidden Markov Models or HMMs is a statistical approach for sequencing classification tasks, such as NER. It involves representing some sequence of words in the text as different states, where every State represents a specific named entity. By analyzing the probabilities, you can identify the named entities from the text.
- Deep learning: Deep learning techniques like neural networks are used in NER tasks. This allows you to identify and categorize named entities efficiently and accurately.
- Conditional Random Fields: These come under a graphical model that is used in sequence labeling tasks. They offer conditional probability modeling of each tag containing the sequence of words. This allows you to identify the named entities in a text.
How Does NER Work?
Named Entity Recognition (NER) operates as an extraction of information. Its functioning is divided into different key steps:
#1. Preprocess the Text
In the first step, NER involves the preparation of textual information for analysis. It generally involves tasks like tokenization. Here, the text at first split into tokens before NER started identifying entities.
For instance, “Bill Gates founded Microsoft” can be split into different tokens like “Bill”, “Gates”, “founded”, and “Microsoft”.
#2. Identify Entities
Potential named entities can be detected by using statistical methods or linguistic rules. This step involves pattern recognition, such as specific formats (dates), or capitalization in names (“Bill Gates”). Once the preprocessing function is completed, NER algorithms scan the text to identify words in the sequences that correspond to the entities.
#3. Classify Entities
After NER identifies the entities, it categorizes these recognized entities into types, classes, or groups. The common categories are organization, date, location, person, and more. This is achieved by machine learning models that are trained on labeled data.
For example, “Bill Gates” would be recognized as a “person” and “Microsoft” as an “organization”.
#4. Contextual Analysis
NER never stops at recognizing and classifying entities. It often considers the context to enhance accuracy. This step considers the context where the entities appear, giving accurate categorization.
For example, “Bill Gates Founded Microsoft”. Here, the context lets the systems identify “Bill” as the name of a person and not the bill of a payment.
#5. Post-Processing
After initial identification and categorization, post-processing is necessary to refine the final results. This involves resolving ambiguities, using knowledge bases, merging multi-token entities, and more to improve entity data.
The amazing part of NER is that it has the ability to interpret and understand unstructured text, which contains the needed piece of data for your business. It receives an essential portion of data from news articles, web pages, research papers, social media posts, and more.
By recognizing and categorizing named entities, NER adds an extra layer of meaning and structure to the textual landscape.
Methods of NER

The most commonly used methods are the following:
#1. Supervised Machine Learning Based Method
This method uses machine learning models that are trained on texts that are pre-labeled by humans with named entity categories.
This approach utilizes algorithms, including maximum entropy and conditional random fields, to get complex statistical language models. It is effective for resolving linguistic meanings along with other complexities, but it needs a large volume of training data to perform the operation.
#2. Rules-Based Systems
This method utilizes different rules to gather information. It includes titles or capitalizations, such as “Er”. In this method, a lot of human intervention is necessary to give input, monitor, and twist the rules. This method might miss the textual variations which are not included in the training annotations. That’s why rules-based systems are unable to deal with complexity and machine learning models.
#3. Dictionary-Based Systems
In this method, a dictionary containing an extensive amount of synonyms and vocabulary collection is used to identify and cross-check named identities. This method faces trouble in categorizing named entities that have various variations in spellings.
Also, there are many other emerging NER methods. Let’s discuss them too:
#4. Unsupervised Machine Learning Systems
These ML systems use machine learning models that are not pre-trained on the text data. The unsupervised learning models are more capable of executing complex jobs than supervised models.
#5. Bootstrapping Systems

Bootstrapping systems are also known as self-supervised systems that categorize the named entities depending on grammatical characteristics, including parts of speech tags, capitalization, and other pre-trained categories.
A human then tweaks the bootstrap system by labeling the predictions of the system as incorrect or correct and adding the right ones to the new training set.
#6. Neural Network Systems
It builds the Named Entity Recognition model by using bidirectional architecture learning models (Bidirectional Encoder Representations from Transformers), neural networks, and encoding techniques. This method minimizes human interaction.
#7. Statistical Systems
This method uses probabilistic models that are trained on textual relationships and patterns. It helps predict named entities easily from new text-based data.
#8. Semantic Role Labeling Systems
This system preprocesses a Named Entity Recognition model using the semantic learning techniques that teach the relationship between the categories and context.
#9. Hybrid Systems
This method is an interesting one that uses aspects of several approaches in a combined manner.
Benefits of NER
NER models provide numerous benefits.
- NER automates the data extraction process for a large volume of data.
- It is used in every industry to extract key information from an unstructured text.
- This can save you and your employees time in performing data extraction tasks.
- It can enhance the accuracy of NLP processes and tasks.
- It ensures data security by hosting custom NER models, eliminating the need to share sensitive information with third-party vendors.
- It accommodates new entity types and terminologies as the domain evolves.
Challenges of NER
- Ambiguity: Many words used in the text can be deceptive. For example, the word “Amazon” refers to a company, a river, and a forest. It can be differentiated by a specific context. Thus, this makes entity recognition a bit trickier.
- Context dependency: Words derived from the surrounding context have different meanings; for example, “Apple” in a tech-based text refers to the corporation, while in surrounding, it refers to fruit. It is not hard to recognize an accurate entity.
- Data sparsity: For ML-based NER methods, the availability of labeled data is essential. However, extracting such data, especially for specialized domains or less common languages, can be challenging.
- Language variations: Human languages have different forms depending on their dialects, regional differences, and slang. Hence, it is difficult to extract the foreign language text.
- Model generalization: The NER models might excel in classifying entities in a single domain but can confuse generalization in another domain. So, NER models can behave differently across different domains.
These challenges can be addressed if you combine advanced algorithms, linguistic expertise, and quality data. Since NER is evolving, research and development teams must refine various techniques to tackle these challenges.
Use Cases of NER
#1. Categorizing Content

Publishing and news houses generate a large volume of online content. So, managing them efficiently is crucial to get the most out of an article or news.
Named Entity Recognition scans the entire content automatically and extracts data like organizations, places, and people names used in the content. Knowing the necessary tags for every article helps you categorize articles in the defined hierarchy, enhancing the content delivery.
#2. Search Algorithms
Suppose you have an internal search algorithm for your online publisher that contains millions of articles. For each search query, your internal search algorithm ends up gathering all the words from those articles. This is a time-consuming process.
Now, if you use NER for your online publisher, it will get the essential entities easily from all the articles and store them separately. This will speed up your search process.
#3. Content Recommendations
Automating the recommendation process is a major use case of NER. Recommendation systems guide in discovery of new ideas and content.
Netflix is the best example of this. It’s proof that building an efficient recommendation system helps you become more event addictive and engaging.
For news publishers, NER works effectively in recommending similar articles. This can be done by gathering tags from a specific article and recommending other content that has similar entities.
#4. Customer Support

For every organization, customer support is a major thing. That’s why there are multiple ways to make the function of customer feedback handling smooth. NER is one of them. Let’s understand this with an example.
Suppose a customer gives feedback “Staff in Adidas outlet store in San Diego is lacking finer details of sport shoes.” Here, NER pulls out the tags “San Diego” (location) and “sport shoes” (product).
Thus, NER is used to classify each complaint and send it to the respective department within the organization to handle the issue. You can develop a database consisting of feedback that is categorized into various departments and analyze each feedback.
#5. Research Papers
An online publication or journal website holds plenty of scholarly articles and research papers. You can find hundreds of papers resembling similar topics with slight modifications. So, organizing all this data in a structured manner can be a complicated task.
To skip the long process, you can segregate these papers based on the relevant tags.
For example, there are thousands of papers on machine learning. To find the one that mentioned the use of convolutional neural networks (CNNs), you need to put entities on them. This will help you find the article quickly as per your requirements.
Conclusion
The NLP technique, Named Entity Recognition (NER), helps in the identification of named entities in an unstructured text and the categorization of these entities into predefined groups like locations, person names, products, and more.
The primary goal of NER is to gather structured information from an unstructured text and represent it in a readable format. It involves various models and processes and brings many benefits to professionals and businesses. It’s also used for various applications apart from NLP.
I hope you understand the above explanation about this technique to be able to implement this in your business and get relevant, valuable information in time.
You may also explore some Best NLP Courses to learn natural language processing