Human languages are difficult to understand for machines, as it involves a lot of acronyms, different meanings, sub-meanings, grammatical rules, context, slang, and many other aspects.
But many business processes and operations leverage machines and require interaction between machines and humans.
So, scientists needed a technology that would help the machine to decode human languages and make it simpler for machines to learn them.
That is when natural language processing or NLP algorithms came into existence. It made computer programs capable of understanding different human languages, whether the words are written or spoken.
NLP makes use of different algorithms for processing languages. And with the introduction of NLP algorithms, the technology became a crucial part of Artificial Intelligence (AI) to help streamline unstructured data.
In this article, I’ll discuss NLP and some of the most talked about NLP algorithms.
Let’s begin!
What is NLP?
Natural language process (NLP) is a field of computer science, linguistics, and artificial intelligence that deals with the interaction between human language and computers. It helps program machines so that they can analyze and process large volumes of data associated with natural languages.

In other words, NLP is a modern technology or mechanism that is utilized by machines to understand, analyze, and interpret human language. It gives machines the ability to understand texts and the spoken language of humans. With NLP, machines can perform translation, speech recognition, summarization, topic segmentation, and many other tasks on behalf of developers.
The best part is that NLP does all the work and tasks in real-time using several algorithms, making it much more effective. It is one of those technologies that blends machine learning, deep learning, and statistical models with computational linguistic-rule-based modeling.
NLP algorithms allow computers to process human language through texts or voice data and decode its meaning for various purposes. The interpretation ability of computers has evolved so much that machines can even understand the human sentiments and intent behind a text. NLP can also predict upcoming words or sentences coming to a user’s mind when they are writing or speaking.
This technology has been present for decades, and with time, it has been evaluated and has achieved better process accuracy. NLP has its roots connected to the field of linguistics and even helped developers create search engines for the Internet. As technology has advanced with time, its usage of NLP has expanded.
Today, NLP finds application in a vast array of fields, from finance, search engines, and business intelligence to healthcare and robotics. Furthermore, NLP has gone deep into modern systems; it’s being utilized for many popular applications like voice-operated GPS, customer-service chatbots, digital assistance, speech-to-text operation, and many more.
How Does NLP Work?
NLP is a dynamic technology that uses different methodologies to translate complex human language for machines. It mainly utilizes artificial intelligence to process and translate written or spoken words so they can be understood by computers.
Like humans have brains for processing all the inputs, computers utilize a specialized program that helps them process the input to an understandable output. NLP operates in two phases during the conversion, where one is data processing and the other one is algorithm development.
Data processing serves as the first phase, where input text data is prepared and cleaned so that the machine is able to analyze it. The data is processed in such a way that it points out all the features in the input text and makes it suitable for computer algorithms. Basically, the data processing stage prepares the data in a form that the machine can understand.
The techniques that are involved in this phase are:

- Tokenization: The input text is segregated into small forms so that it is suitable for NLP to work on them.
- Stop Word Removal: The stop word removal technique removes all the familiar words from the text and transforms them into a form that retains all the information at a minimal state.
- Lemmatization and Stemming: Lemmatization and stemming causes words to get diminished to their root structure so that it is easy for machines to process them.
- Part-of-Speech Tagging: In this way, the input words are marked based on their noun, adjectives, and verbs, and then they are processed.
After the input data has gone through the first phase, next, the machine develops an algorithm where it can finally process it. Among all the NLP algorithms that are used for processing the preprocessed words, rule-based and machine-learning-based systems are widely used:
- Rule-Based Systems: Here, the system utilizes linguistic rules for the final processing of the words. It is an old algorithm that is still being used on a large scale.
- Machine Learning-Based Systems: This is an advanced algorithm combining neural networks, deep learning, and machine learning to decide its own rule for processing words. Since it utilizes statistical methods, the algorithm decides the processing of words based on the training data, and it makes changes as it proceeds.
NLP Algorithms Categories
NLP algorithms are ML-based algorithms or instructions that are used while processing natural languages. They are concerned with the development of protocols and models that enable a machine to interpret human languages.

NLP algorithms can modify their shape according to the AI’s approach and also the training data they have been fed with. The main job of these algorithms is to utilize different techniques to efficiently transform confusing or unstructured input into knowledgeable information that the machine can learn from.
Along with all the techniques, NLP algorithms utilize natural language principles to make the inputs better understandable for the machine. They are responsible for assisting the machine to understand the context value of a given input; otherwise, the machine won’t be able to carry out the request.
NLP algorithms are segregated into three different core categories, and AI models choose any one of the categories depending on the data scientist’s approach. These categories are:
#1. Symbolic Algorithms
Symbolic algorithms serve as one of the backbones of NLP algorithms. These are responsible for analyzing the meaning of each input text and then utilizing it to establish a relationship between different concepts.

Symbolic algorithms leverage symbols to represent knowledge and also the relation between concepts. Since these algorithms utilize logic and assign meanings to words based on context, you can achieve high accuracy.
Knowledge graphs also play a crucial role in defining concepts of an input language along with the relationship between those concepts. Due to its ability to properly define the concepts and easily understand word contexts, this algorithm helps build XAI.
However, symbolic algorithms are challenging to expand a set of rules owing to various limitations.
#2. Statistical Algorithms
Statistical algorithms can make the job easy for machines by going through texts, understanding each of them, and retrieving the meaning. It is a highly efficient NLP algorithm because it helps machines learn about human language by recognizing patterns and trends in the array of input texts. This analysis helps machines to predict which word is likely to be written after the current word in real-time.
From speech recognition, sentiment analysis, and machine translation to text suggestion, statistical algorithms are used for many applications. The main reason behind its widespread usage is that it can work on large data sets.
Moreover, statistical algorithms can detect whether two sentences in a paragraph are similar in meaning and which one to use. However, the major downside of this algorithm is that it is partly dependent on complex feature engineering.
#3. Hybrid Algorithms
This type of NLP algorithm combines the power of both symbolic and statistical algorithms to produce an effective result. By focusing on the main benefits and features, it can easily negate the maximum weakness of either approach, which is essential for high accuracy.

There are many ways where both approaches can be leveraged:
- Symbolic supporting machine learning
- Machine learning supporting symbolic
- Symbolic and machine learning working in parallel
Symbolic algorithms can support machine learning by helping it to train the model in such a way that it has to make less effort to learn the language on its own. Although machine learning supports symbolic ways, the machine learning model can create an initial rule set for the symbolic and spare the data scientist from building it manually.
However, when symbolic and machine learning works together, it leads to better results as it can ensure that models correctly understand a specific passage.
Best NLP Algorithms
There are numerous NLP algorithms that help a computer to emulate human language for understanding. Here are the best NLP algorithms you can use:
#1. Topic Modeling
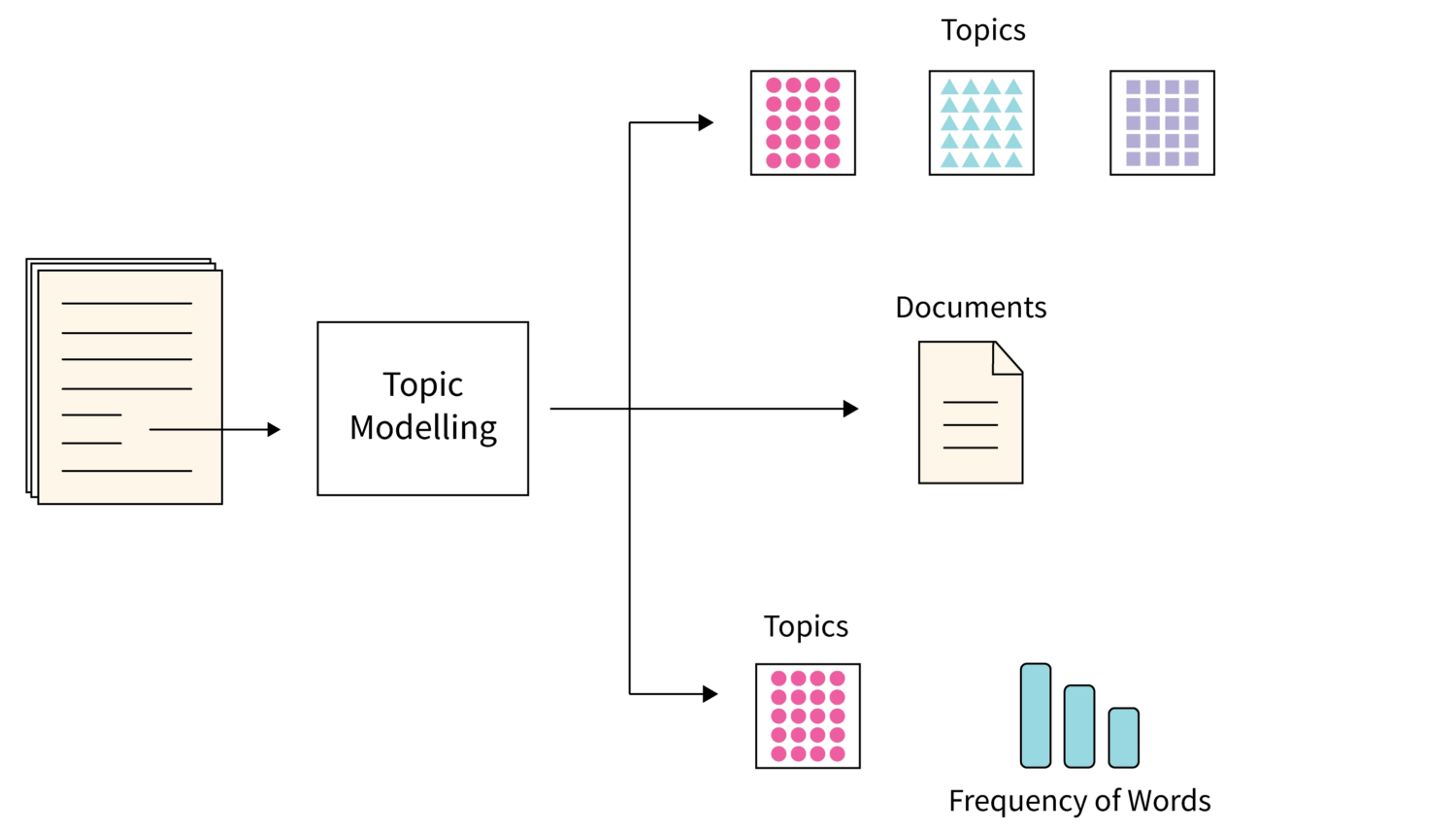
Topic modeling is one of those algorithms that utilize statistical NLP techniques to find out themes or main topics from a massive bunch of text documents.
Basically, it helps machines in finding the subject that can be utilized for defining a particular text set. As each corpus of text documents has numerous topics in it, this algorithm uses any suitable technique to find out each topic by assessing particular sets of the vocabulary of words.
Latent Dirichlet Allocation is a popular choice when it comes to using the best technique for topic modeling. It is an unsupervised ML algorithm and helps in accumulating and organizing archives of a large amount of data which is not possible by human annotation.
#2. Text Summarization
It is a highly demanding NLP technique where the algorithm summarizes a text briefly and that too in a fluent manner. It is a quick process as summarization helps in extracting all the valuable information without going through each word.
The summarization can be done in two ways:
- Extraction-based summarization: It causes the machine to extract only the main words and phrases from the document without modifying the original.
- Abstraction-based summarization: In this process, new words and phrases are created from the text document, which depicts all the information and intent.
#3. Sentimental Analysis
It’s the NLP algorithm that aids a machine in comprehending the meaning or the intent behind a text from the user. It is widely popular and used in different AI models of businesses because it helps companies understand what customers think about their products or service.
By understanding the intent of a customer’s text or voice data on different platforms, AI models can tell you about a customer’s sentiments and help you approach them accordingly.
#4. Keyword Extraction
Keyword extraction is another popular NLP algorithm that helps in the extraction of a large number of targeted words and phrases from a huge set of text-based data.
There are different keyword extraction algorithms available which include popular names like TextRank, Term Frequency, and RAKE. Some of the algorithms might use extra words, while some of them might help in extracting keywords based on the content of a given text.
Each of the keyword extraction algorithms utilizes its own theoretical and fundamental methods. It is beneficial for many organizations because it helps in storing, searching, and retrieving content from a substantial unstructured data set.
#5. Knowledge Graphs
When it comes to choosing the best NLP algorithm, many consider knowledge graph algorithms. It is an excellent technique that utilizes triples for storing information.
This algorithm is basically a blend of three things – subject, predicate, and entity. However, the creation of a knowledge graph isn’t restricted to one technique; instead, it requires multiple NLP techniques to be more effective and detailed. The subject approach is used for extracting ordered information from a heap of unstructured texts.
#6. TF-IDF
TF-IDF is a statistical NLP algorithm that is important in evaluating the importance of a word to a particular document belonging to a massive collection. This technique involves the multiplication of distinctive values, which are:
- Term frequency: The term frequency value gives you the total number of times a word comes up in a particular document. Stop words generally get a high term frequency in a document.
- Inverse document frequency: Inverse document frequency, on the other hand, highlights the terms that are highly specific to a document or words that occur less in a whole corpus of documents.
#7. Words Cloud
Words Cloud is a unique NLP algorithm that involves techniques for data visualization. In this algorithm, the important words are highlighted, and then they are displayed in a table.
The essential words in the document are printed in larger letters, whereas the least important words are shown in small fonts. Sometimes the less important things are not even visible on the table.
Learning Resources
Apart from the above information, if you want to learn about natural language processing (NLP) more, you can consider the following courses and books.
#1. Data Science: Natural Language Processing in Python

This course by Udemy is highly rated by learners and meticulously created by Lazy Programmer Inc. It teaches everything about NLP and NLP algorithms and teaches you how to write sentiment analysis. With a total length of 11 hours and 52 minutes, this course gives you access to 88 lectures.
#2. Natural Language Processing: NLP With Transformers in Python
With this popular course by Udemy, you will not only learn about NLP with transformer models but also get the option to create fine-tuned transformer models. This course gives you complete coverage of NLP with its 11.5 hours of on-demand video and 5 articles. In addition, you will learn about vector-building techniques and preprocessing of text data for NLP.
#3. Natural Language Processing With Transformers
This book was first released in 2017 and aimed to help data scientists and coders learn about NLP.
| Preview | Product | Rating | |
|---|---|---|---|

|
Natural Language Processing with Transformers, Revised Edition | Buy on Amazon |
Once you start reading the book, you will get to build and optimize transformer models for many NLP tasks. You will also get to know how you can utilize transformers for cross-lingual transfer learning.
#4. Practical Natural Language Processing
Through this book, the authors have explained the tasks, problems, and solution approaches for NLP.
| Preview | Product | Rating | |
|---|---|---|---|

|
Practical Natural Language Processing: A Comprehensive Guide to Building Real-World NLP Systems | Buy on Amazon |
This book also teaches about implementing and evaluating different NLP applications.
Conclusion
NLP is an integral part of the modern AI world that helps machines understand human languages and interpret them.
NLP algorithms come helpful for various applications, from search engines and IT to finance, marketing, and beyond.