Message brokers are intermediary systems in network communication that enable network solutions to exchange messages and communicate with each other.
Message brokers form a shared integration mechanism to subsidize cloud-native, serverless, microservices-based, and hybrid cloud architectures.
The Message Broker achieves this by transforming messages between authorized messaging protocols. This encourages interdependent services to instantly talk to one another, regardless of their diverse programming languages.

Below, we have put together the popular message brokers you can choose from to facilitate communication between modern apps.
Top Message Brokers
Solace PubSub+
PubSub+, a message broker offered by Solace is one of the long-time leaders in the message-oriented middleware space. Its mission is simple: to enable your real-time business with event-driven integration.
It mediates message delivery, so your applications can send and receive messages in their native format thanks to a rich set of APIs, support for open APIs and protocols, and connectors for popular applications, cloud services and integration technologies.
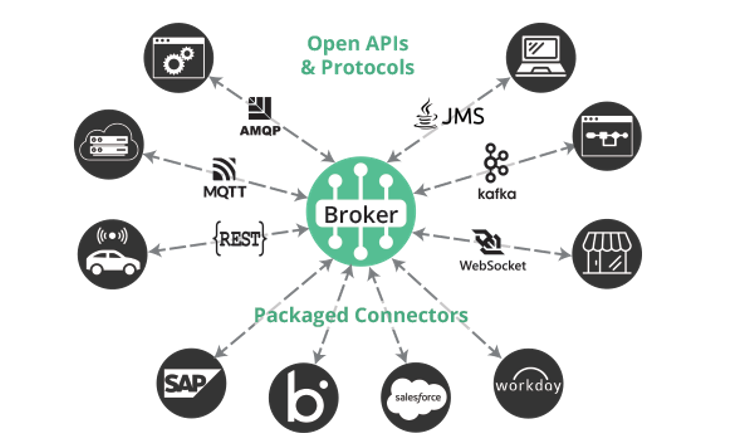
PubSub+ is extremely versatile, with supports for publish/subscribe, queuing, request/reply, and streaming, along with persistent and non-persistent delivery. It’s also powerful: users can take advantage of advanced messaging features like caching, hierarchical topics with wildcards, partitioned queues, replay, time to live and more.
Finally, an integrated Kafka bridge lets messages flow between Kafka environments and assets, while Solace’s event portal software gives you the tools to easily discover and manage event streams. As a component of PubSub+ Platform, it lets you link many of these fully interoperable brokers into an “event mesh” that dynamically routes messages across environments and around the world, even in the event of application failures and network outages.
It’s available as free software (with a paid support option), a cloud-managed service, and an appliance, depending on the needs of your organization.
Memphis
Memphis is an open-source message broker especially built for developers to employ in in-app streaming use cases. It can be easily deployed and scales your data-driven app within a few seconds.
Developers have ensured that the users can avail the benefits offered by other message brokers and more from Memphis. This message broker utilizes the functionalities of NATS core to offer automatic optimization techniques, schema management, inline processing, and troubleshooting abilities.

This community-driven message broker features a user-friendly interface fully optimized to deliver exceptional performance. Memphis is equipped with CLI and SDKs for Node.JS, Go, Python, Typescript, and NestJS enabling developers to integrate the message broker functionalities on their platform.
It offers a dead letter queue feature with automatic message retransmission facilities to notify unprocessed messages.
Key features of Memphis:
- Runs on Kubernetes to support full hardware abstraction for scaling, upgrading, rebooting, and more.
- Troubleshooting the unconsumed message is easy by accessing the data journey of every message.
- Intuitive UI and CLI are handy for data engineers to troubleshoot errors in real time.
- Contains Unique schema management and inline transformation abilities.
RabbitMQ
Released in 2007, RabbitMQ is one of the best message brokers, widely used by thousands of users worldwide as a message intermediator. Written in the Erlang programming language, it is incredibly lightweight and can be installed in both cloud and on-premises-based setups.

RabbitMQ is highly reliable and intuitive, and its user-friendly interface enables applications to exchange messages and control the message broker easily. This powerful message broker is compatible with many developer platforms and supports many message protocols. It can be easily deployed in distributed and federated configurations to cater to high-scale requirements.
The message broker is interoperable and works on several operating systems, cloud-based platforms, and developer tools. The major languages supported are Java, .NET, PHP, Python, JavaScript, Ruby, and Go. It has various features and supports plugins that facilitate integration and interaction with other systems.
Being an open-source message broker, RabbitMQ is entirely free. A separate commercial release is also available for a subscription fee.
Apache Kafka
Next, we have Apache Kafka, a robust message broker offering better throughput, in-built partitioning, replication, and fault tolerance than other messaging brokers. Kafka uses the distributed system technique that employs the TCP protocol to allow communication between clients and servers.
This guarantees speedy performance making Kafka an ideal solution to fulfill the communication needs of large message processing applications.

Apache Kafka can be deployed on both on-premises and cloud-based systems, and it works flawlessly on bare metal, virtual machines, and containers. It generally finds its use where it is required to isolate the processing and data producers, buffer the undelivered messages, and in similar scenarios.
This open-source message broker was initially built to track website activities and store extensive data. Its ability to store large volumes of data in a distributed and fault-tolerant cluster makes it the perfect choice for large tech companies. The Kafka Message Broker can skilfully manage real-time event streaming, pipelining and data replay required in fast operating scenarios.
Apache ActiveMQ
Based on Java, Apache ActiveMQ is an open-source message broker capable of administering the setup and maintenance on your behalf, reducing your workload.
It supports all the major standard protocols used in the industry and allows seamless integration with multiple platforms using the popular AMQP protocol.
Similarly, the STOMP protocol facilitates the message exchange between the web applications through the WebSockets, and the MQTT protocol allows the message exchange between IoT devices.

It is compatible with numerous cross-language platforms and clients built in different languages, including JavaScript, C, C++, Python, .Net, and more.
It supports advanced features like message groups, combined queues, and clustering, to name a few. ActiveMQ is highly flexible and versatile enough to implement in different messaging use cases quickly.
ActiveMQ is available in two variants- the “classic” broker and the advanced version known as Artemis.
Classic ActiveMQ is built on the endless pluggable architecture and is compatible with several generations of messaging apps. On the other hand, Artemis, the advanced version of ActiveMQ, flaunts a non-blocking architecture for delivering the high performance demanded by the new generation of apps.
WSO2
WSO2 is the next message broker worth checking out, created with the intent of offering message broking capabilities in a distributed environment.
Extremely lightweight and easy to use, this message broker is equipped with a continuous availability mode that ensures high availability and expands servers within the cluster, thereby minimizing the chance of a single point of failure.
The open source technology efficiently manages multiple queues, subscribers, and messages to facilitate persistent messaging.
WSO2 supports multiple protocols, including MQTT, a lightweight machine-to-machine network protocol that offers enterprise messaging features in IoT.
It bridges remote devices with the brokers, enabling machine-to-machine (M2M) communications which can generate tens of thousands of simultaneous events every second. WSO2 works on a flexible deployment model offering single-node execution features to cluster deployments.
The notable features of WSO2 are as follows:
- Supports JMS v1.0 and v1.1 API
- Complies with the set of standards.
- Supports Advanced Message Queuing Protocol (AMQP) v0.91 and MQTT protocol for all QoS levels and retained messaging.
- Supports many languages/platforms, including Java, .Net, C, C++, PHP, Ruby, Erlang, and more.
ZeroMQ
Lastly, we have ZeroMQ, a sophisticated message broker that offers high-speed connections between applications regardless of the language and platform they run on.
It consists of async input output engines loaded on messaging libraries and establishes a many-to-many relationship between the sender and receiver.
It transmits messages from one application to another across WebSockets with the help of numerous transport channels like in-process, inter-process, TCP, multicast, TIPC, IPC, and UDP.

ZeroMQ is equipped with all the features present in a standard distributed messaging system and sends messages over inter-connectable sockets, which can be arranged in different patterns like pub-sub, request-reply, task distribution, and fan-out.
ZeroMQ allows a high degree of customization to meet the unique demands of different use cases and supports multiple messaging patterns and language implementations.
It is compatible with diverse programming languages, the prominent ones being C, C++, C#, Java, Python, Ruby, and Perl.
The message broker is extremely fast, open source, and has a lightweight messaging library which helps perform exceptionally well even with asynchronous input-output engines.
Let’s now look at how message brokers work and the benefits of using message brokers.
How do Message Brokers work?

Message brokers can secure, archive, route, and dispatch messages to the appropriate recipients. They operate as a bridge between various applications, allowing senders to send messages without being familiar with the location, activity, or number of recipients.
Message brokers often rely on an element known as a message queue to provide reliable message storage and secure delivery. The message queue stores and indexes the messages until the consuming applications can process them. Messages are kept in a message queue the same way they were transferred and stay there until receipt is verified.
To have a better idea of how message brokers perform their tasks, let’s understand some of its fundamental concepts:
- The Producer is an interface that directly communicates with the Message Broker to send the stored messages for distribution.
- A Consumer is an entity where the message has to be delivered and demands data from the message broker. You can also refer to them as subscribers.
- Queue or a Topic is a data type used by message brokers to store messages. You can consider them a folder in the computers, and they operate in the FIFO(First in First out) fashion.
- Lastly, we have an Exchanger, a sort of logical entity that manages the queues and creates groups of messages enabling the consumers to exchange messages.
Communication through the exchange of messages using Message brokers is carried out based on two distinct messaging patterns or styles. They are known as Point-to-point messaging and Publish/subscribe messaging.
Point-to-point messaging: This communication model is the distribution pattern used in message queues where the sender and recipient of each message are associated on a one-to-one basis. Every message in the queue is read only once and only sent to one recipient.
Point-to-point messaging model is implemented in Payroll management and Financial Transaction Processing scenarios where assurance needs to be provided that each payment is made only once. If the consumer is offline, the message broker stores it in the message queue and delivers it at a later time.
Publish/subscribe messaging: In this mode of message exchange, the producer is completely unaware of who will be the consumer of the message. It sends messages concerning a topic, and all applications that have subscribed to it receive all published messages.
The consumer and producer have a one-to-many relationship, and the model is used in the event-driven architecture-based system, where applications have no dependencies on each other.
Here is a life cycle of a message transmission using a message broker.
- The cycle starts with sending messages to single or several destinations.
- Then convert messages to a different model.
- Split messages into smaller parts, transmit them to the consumer, and then collects the answers and convert them into a single message to send back to the user.
- Use third-party storage to add to or store a message.
- Fetch the required data using the web services
- Send responses in case of message failure or errors.
- Use the publish-subscribe pattern to route messages based on content and topic.
Benefits of using Message Brokers

Here are the benefits of employing message brokers in the network:
- The producer and consumer can exchange messages regardless of whether the other one is online. A message broker will deliver the message whenever the consumer becomes active.
- Message brokers guarantee message delivery in every situation, and the acknowledgment mechanism reports to the producer about the delivery, making the technology highly durable and persistent.
- The asynchronous processing ensures that the tasks demanding many system resources are entrusted to different processes. This speeds up your application and improves the user experience.
- Message brokers redeliver the messages not delivered due to failure. Resent is either attempted immediately or later at some point in time. If the messages remain undelivered after numerous attempts, the messages are re-routed to the producer.
Summing Up
So, we now have a pretty clear idea of how deploying message brokers in the system can greatly improve the overall communication architecture. There are plenty of reliable message broker vendors, and we have listed the most popular message brokers capturing the market.
You can employ any of the message brokers that you find capable of fulfilling the data management needs of your organization and help distribute messages between your apps.
You may also explore the best SMS API to send messages to your users.