Regression and classification are two of the most fundamental and significant areas of machine learning.
It can be tricky to distinguish between Regression and Classification algorithms when you’re just getting into machine learning. Understanding how these algorithms work and when to use them can be crucial for making accurate predictions and effective decisions.
First, Let’s see about machine learning.
What is Machine learning?

Machine learning is a method of teaching computers to learn and make decisions without being explicitly programmed. It involves training a computer model on a dataset, allowing the model to make predictions or decisions based on patterns and relationships in the data.
There are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
In Supervised learning, the model is provided with labeled training data, including input data and the corresponding correct output. The goal is for the model to make predictions about the output for new, unseen data based on the patterns it learned from the training data.
In Unsupervised learning, the model is not given any labeled training data. Instead, it is left to discover patterns and relationships in the data independently. This can be used to identify groups or clusters in the data or to find anomalies or unusual patterns.
And in Reinforcement Learning, an agent learns to interact with its environment to maximize a reward. It involves training a model to make decisions based on the feedback it receives from the environment.

Machine learning is used in various applications, including image and speech recognition, natural language processing, fraud detection, and self-driving cars. It has the potential to automate many tasks and improve decision-making in various industries.
This article mainly focuses on Classification and Regression concepts, which come under supervised machine learning. Let’s get started!
Classification in Machine Learning

Classification is a machine-learning technique that involves training a model to assign a class label to a given input. It is a supervised learning task, which means that the model is trained on a labeled dataset that includes examples of the input data and the corresponding class labels.
The model aims to learn the relationship between the input data and the class labels to predict the class label for new, unseen input.
There are many different algorithms that can be used for classification, including logistic regression, decision trees, and support vector machines. The choice of algorithm will depend on the characteristics of the data and the desired performance of the model.
Some common classification applications include spam detection, sentiment analysis, and fraud detection. In each of these cases, the input data might include text, numerical values, or a combination of both. The class labels could be binary (e.g., spam or not spam) or multi-class (e.g., positive, neutral, negative sentiment).
For example, consider a dataset of customer reviews of a product. The input data might be the text of the review, and the class label might be a rating (e.g., positive, neutral, negative). The model would be trained on a dataset of labeled reviews and then would be able to predict the rating of a new review that it had not seen before.
ML Classification Algorithms Types
There are several types of classification algorithms in machine learning:
Logistic Regression
This is a linear model used for binary classification. It is used to predict the probability of a certain event occurring. The goal of logistic regression is to find the best coefficients (weights) that minimize the error between the predicted probability and the observed outcome.
This is done by using an optimization algorithm, such as gradient descent, to adjust the coefficients until the model fits the training data as well as possible.
Decision Trees
These are tree-like models that make decisions based on feature values. They can be used for both binary and multi-class classification. Decision trees have several advantages, including their simplicity and interoperability.
They are also fast to train and make predictions, and they can handle both numerical and categorical data. However, they can be prone to overfitting, especially if the tree is deep and has many branches.
Random Forest Classification
Random Forest Classification is an ensemble method that combines the predictions of multiple decision trees to make a more accurate and stable prediction. It is less prone to overfitting than a single decision tree because the predictions of the individual trees are averaged, which reduces the variance in the model.
AdaBoost
This is a boosting algorithm that adaptively changes the weight of misclassified examples in the training set. It is often used for binary classification.

Naïve Bayes
Naïve Bayes is based on Bayes’ theorem, which is a way of updating the probability of an event based on new evidence. It is a probabilistic classifier often used for text classification and spam filtering.
K-Nearest Neighbor
K-Nearest Neighbors (KNN) is used for classification and regression tasks. It is a non-parametric method that classifies a data point based on the class of its nearest neighbors. KNN has several advantages, including its simplicity and the fact that it is easy to implement. It can also handle both numerical and categorical data, and it does not make any assumptions about the underlying data distribution.
Gradient Boosting
These are ensembles of weak learners that are trained sequentially, with each model trying to correct the mistakes of the previous model. They can be used for both classification and regression.
Regression in Machine Learning

In machine learning, regression is a type of supervised learning where the goal is to predict a c dependent variable based on one or more input features (also called predictors or independent variables).
Regression algorithms are used to model the relationship between the inputs and the output and make predictions based on that relationship. Regression can be used for both continuous and categorical dependent variables.
In general, the goal of regression is to build a model that can accurately predict the output based on the input features and to understand the underlying relationship between the input features and the output.
Regression analysis is used in various fields, including economics, finance, marketing, and psychology, to understand and predict the relationships between different variables. It is a fundamental tool in data analysis and machine learning and is used to make predictions, identify trends, and understand the underlying mechanisms that drive the data.
For example, in a simple linear regression model, the goal might be to predict the price of a house based on its size, location, and other features. The size of the house and its location would be the independent variables, and the price of the house would be the dependent variable.
The model would be trained on input data that includes the size and location of several houses, along with their corresponding prices. Once the model is trained, it can be used to make predictions about the price of a house, given its size and location.
ML Regression Algorithms Types
Regression algorithms are available in various forms, and the usage of each algorithm depends on the number of parameters, such as the kind of attribute value, the pattern of the trendline, and the number of independent variables. Regression techniques that are often used include:
Linear Regression
This simple linear model is used to predict a continuous value based on a set of features. It is used to model the relationship between the features and the target variable by fitting a line to the data.
Polynomial Regression
This is a non-linear model that is used to fit a curve to the data. It is used to model relationships between the features and the target variable when the relationship is not linear. It is based on the idea of adding higher-order terms to the linear model to capture non-linear relationships between the dependent and independent variables.
Ridge Regression
This is a linear model that addresses overfitting in linear regression. It is a regularized version of linear regression that adds a penalty term to the cost function to reduce the complexity of the model.
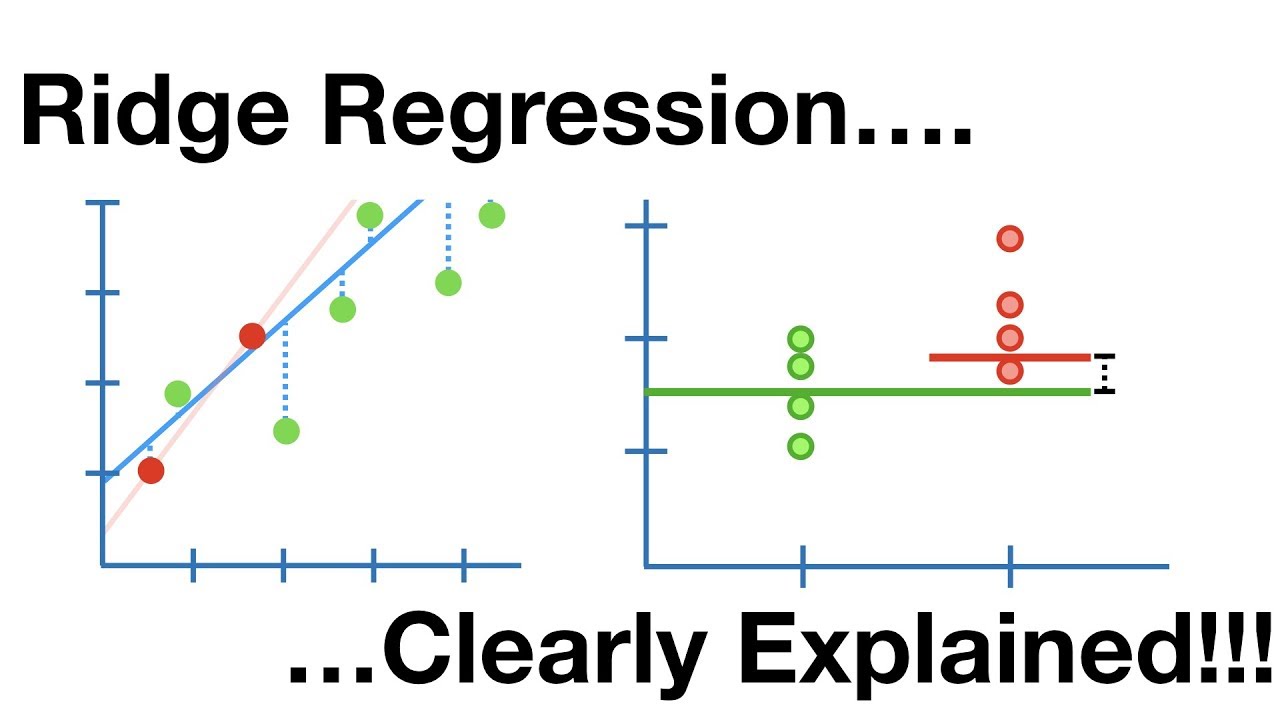
Support Vector Regression
Like SVMs, Support Vector Regression is a linear model that tries to fit the data by finding the hyperplane that maximizes the margin between the dependent and independent variables.
However, unlike SVMs, which are used for classification, SVR is used for regression tasks, where the goal is to predict a continuous value rather than a class label.
Lasso Regression
This is another regularized linear model used to prevent overfitting in linear regression. It adds a penalty term to the cost function based on the absolute value of the coefficients.
Bayesian Linear Regression
Bayesian Linear Regression is a probabilistic approach to linear regression based on Bayes’ theorem, which is a way of updating the probability of an event based on new evidence.
This regression model aims to estimate the posterior distribution of the model parameters given the data. This is done by defining a prior distribution over the parameters and then using Bayes’ theorem to update the distribution based on the observed data.
Regression vs. Classification
Regression and classification are two types of supervised learning, which means that they are used to predict an output based on a set of input features. However, there are some key differences between the two:
| Regression | Classification | |
| Definition | A type of supervised learning that predicts a continuous value | A type of supervised learning that predicts a categorical value |
| Output type | Continuous | Discrete |
| Evaluation metrics | Mean squared error (MSE), root mean squared error (RMSE) | Accuracy, precision, recall, F1 score |
| Algorithms | Linear regression, Lasso, Ridge, KNN, Decision Tree | Logistic regression, SVM, Naïve Bayes, KNN, Decision Tree |
| Model complexity | Less complex models | More complex models |
| Assumptions | Linear relationship between features and target | No specific assumptions about the relationship between features and target |
| Class imbalance | Not applicable | It can be a problem |
| Outliers | Can affect the model’s performance | Not usually a problem |
| Feature importance | Features are ranked by importance | Features are not ranked by importance |
| Example applications | Predicting prices, temperatures, quantities | Predicting whether email spam, predicting customer churn |
Learning Resources
It might be challenging to choose the best online resources for understanding machine learning concepts. We’ve examined the popular courses provided by reliable platforms to present you with our recommendations for the top ML courses on regression and classification.
#1. Machine Learning Classification Bootcamp in Python
This is a course offered on the Udemy platform. It covers a variety of classification algorithms and techniques, including decision trees and logistic regression, and supports vector machines.

You can also learn about topics such as overfitting, bias-variance tradeoff, and model evaluation. The course uses Python libraries such as sci-kit-learn and pandas to implement and evaluate machine learning models. So, basic python knowledge is required to get started with this course.
#2. Machine Learning Regression Masterclass in Python
In this Udemy course, The trainer Covers the basics and underlying theory of various regression algorithms, including linear regression, polynomial regression, and Lasso & Ridge regression techniques.

By the end of this course, you will be able to implement regression algorithms and assess the performance of trained Machine learning models using various Key Performance indicators.
Wrapping Up
Machine learning algorithms can be very useful in many applications, and they can help automate and streamline many processes. ML algorithms use statistical techniques to learn patterns in data and make predictions or decisions based on those patterns.
They can be trained on large amounts of data and can be used to perform tasks that would be difficult or time-consuming for humans to do manually.
Each ML algorithm has its strengths and weaknesses, and the choice of algorithm depends on the nature of the data and the requirements of the task. It’s important to choose the appropriate algorithm or combination of algorithms for the specific problem you are trying to solve.
It’s important to choose the right type of algorithm for your problem, as using the wrong type of algorithm can lead to poor performance and inaccurate predictions. If you are unsure which algorithm to use, it can be helpful to try both regression and classification algorithms and compare their performance on your dataset.
I hope you found this article helpful in learning Regression vs. Classification in Machine Learning. You may also be interested in learning about top Machine Learning models.