You’re likely familiar with voice assistants like Alexa, Siri, and Google Assistant, but have you ever wondered how these voices are generated? Speech synthesis helps these devices generate these AI voices.
It’s estimated that as of 2020, as many as 4.2 billion voice assistant devices are being used worldwide, and that number is expected to reach 8 billion by 2024.
Understanding and implementing speech recognition can revolutionize how businesses operate, interact with customers, and stay competitive in a technologically evolving landscape.
In this article, I will explain what speech synthesis is, how it can be helpful for businesses, the applications of speech synthesis, how speech synthesis works, and the challenges and ethical considerations associated with it.
What is Speech Synthesis?
Speech synthesis, or text-to-speech, is a field of artificial intelligence that focuses on creating human-like speech or voice using a combination of methods.

By combining advanced algorithms and machine learning, AI voices can now interpret written text and transform it into spoken words. This groundbreaking technology has evolved, enabling computers and electronic devices to engage with users through human-like speech in various applications.
Methods Involved in Speech Synthesis
The development of AI voices involves different steps, but the methods used can be broken down into three main approaches:
#1. Machine Learning Algorithms
Machine learning algorithms form the core of AI voice development. Supervised learning is often employed, where AI voice models are trained using large datasets of human speech. These datasets serve as a treasure trove of linguistic patterns, phonetic structures, and speech dynamics.
Through the process of supervised learning, the AI model gains the ability to identify patterns and correlations between provided textual inputs and the associated speech outputs.
As it processes more data, it refines its understanding of phonetics, intonations, and other speech characteristics, resulting in increasingly natural and expressive AI voices.
#2. Natural Language Processing (NLP)
Natural Language Processing is a critical aspect of AI voice technology that enables machines to understand and interpret human language. NLP acts like a language detective, dissecting written words and sentences to discern grammar, meaning, and emotions.

NLP ensures that AI voices can interpret and speak complex sentences, even when words have multiple meanings or sound similar. It acts as the bridge between written words and spoken speech, making AI voices sound remarkably human, regardless of the intricacies of language patterns.
#3. Speech Synthesis Techniques
Speech synthesis techniques are fundamental to AI voices, enabling machines to transform processed text into understandable and expressive speech. Different methods exist, such as concatenative synthesis (piecing together recorded speech) and formant synthesis (relies on modeling the vocal tract as a set of resonant frequencies or formats)
Neural TTS (Text-To-Speech) leverages deep learning models, including neural networks, to generate speech from text. This method captures intricate details like rhythm and tone, making AI voices sound exceptionally natural and expressive.

Neural TTS represents a significant advancement, bringing AI voices closer to the nuanced qualities of human speech.
Now, Let’s understand all the steps involved in speech synthesis in brief.
Speech Synthesis Process
Analyzing Text
The process begins with analyzing the input text. This involves breaking down the text into phonemes (the smallest units of sound), identifying words, and understanding the syntactic and semantic structure.
Applying Linguistic Rules
Linguistic rules and models are applied to determine pronunciation, stress patterns, and intonation. This step involves ensuring that the synthesized speech sounds natural and coherent.
Modeling
Acoustic models are used to represent the sound characteristics of speech. Traditional methods involved defining the resonance frequencies of the vocal tract (formant synthesis). Modern approaches use statistical parametric synthesis or deep learning to model complex relationships between text and speech features.
Training
AI voice models are trained on extensive datasets of recorded human speech. This training allows the model to learn the nuances of natural speech, including variations in pitch, speed, and expression.
Using Neural Networks
Deep learning, specifically neural networks, is a key technology in modern AI voice synthesis. Models like Tacotron and WaveNet use neural networks to generate spectrograms or directly produce the waveform of speech from text inputs.
Waveform Synthesis
Waveform synthesis is the process of turning the information from the spectrogram into the actual speech signal. Techniques like WaveNet generate high-quality, natural-sounding waveforms.
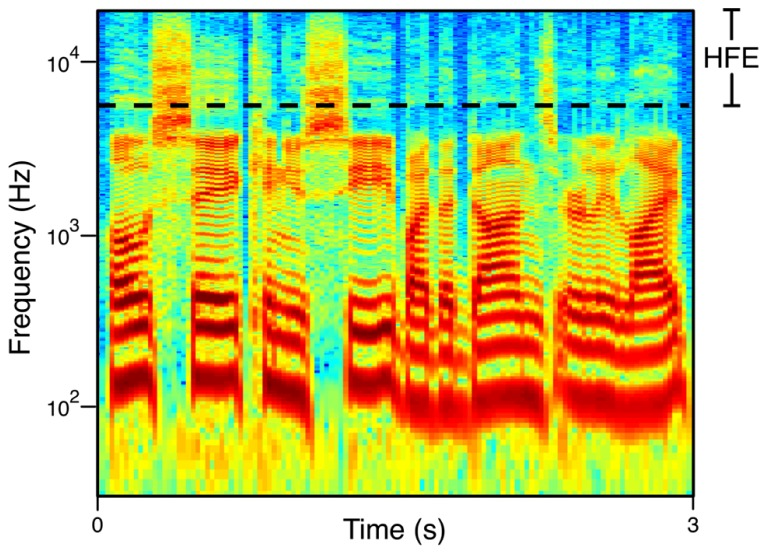
Applying Post-Processing Techniques
After synthesis, post-processing techniques may be applied to refine the output. This can involve adjusting pitch and duration or adding effects to enhance naturalness.
Output
The final output is AI-generated speech that corresponds to the input text.
Some models employ transfer learning, where pre-trained models are fine-tuned for specific voices or languages. This helps in achieving more personalized and context-aware voices.
Speech Synthesis systems often undergo continual improvement through feedback loops. User interactions, corrections, and preferences contribute to refining the models over time.
Real-Life Applications of Speech Synthesis
- Language Learning: Language learning applications use speech synthesis to pronounce words and phrases. Learners can listen to correct pronunciations and practice their listening skills, enhancing the overall language learning experience. (Example: Duolingo)
- Virtual Assistants: Virtual assistants leverage speech synthesis to provide natural and conversational responses to user queries. Users can interact with these assistants through spoken language, making tasks like setting reminders, checking the weather, or controlling smart devices hands-free. (Examples: Siri, Google Assistant, Alexa)
- GPS Navigation Systems: When you’re driving and need directions, AI voices in GPS systems act like a friendly guide, giving turn-by-turn instructions. They help you reach your destination safely, providing real-time updates and suggesting the best routes. AI voices make your road trips smoother and safer.
- Screen Readers: Speech synthesis is extensively used in screen readers for visually impaired individuals. These tools convert on-screen text into spoken words, enabling users to navigate websites, read documents, read articles, and interact with digital content. (Examples: Google, Medium.com)
- Podcasting and Audio Content Creation: Content creators use speech synthesis tools to generate voiceovers for podcasts, audiobooks, and other audio content. This can save time and resources, especially when a specific tone or style is desired for narration.
- Smart Home Devices: Smart home devices utilize speech synthesis to communicate with users. These devices can provide updates, answer questions, and execute commands through synthesized voices, enhancing user interaction in smart home environments. (Examples: Amazon Echo, Google Home)
Moreover, it is beneficial for many businesses.
How Speech Synthesis Can Be Helpful For Businesses
Speech synthesis can offer various benefits to businesses, enhancing communication, customer interaction, and overall efficiency.
Here are some of the common examples:
- Create Digital Content: Speech synthesis can make digital content more accessible to a broader audience, including individuals with visual impairments. Businesses can use this technology to provide spoken descriptions of visual content on websites, apps, or documents, ensuring inclusivity and compliance with accessibility standards.
- Multilingual Communication: Businesses operating in diverse regions or catering to an international audience can benefit from multilingual speech synthesis. This allows for the creation of voice interfaces and communication systems that can dynamically switch between languages, improving communication with customers and partners globally.
- Customer Service and Support: Customers can get information, make inquiries, or resolve issues using natural and automated voice prompts, improving the efficiency of customer service.
- Voice Assistants and Smart Devices: Integrating speech synthesis into voice-activated assistants or smart devices can enhance user interactions. Businesses can develop applications that allow users to access information, place orders, or control devices through spoken commands, creating seamless and user-friendly experiences.
- Interactive Voice Response (IVR) Systems: Automated customer service systems often use speech synthesis to guide users through menu options, provide information, and handle routine inquiries.
- Training and Learning Programs: Speech synthesis can be used to enhance training and e-learning programs. It can generate natural-sounding voices to narrate training materials, making content more engaging and accessible. This is particularly useful for onboarding, compliance training, or educational content.
- Brand Voice and Identity: Businesses can establish a unique brand voice and identity by using customized and recognizable synthesized voices. This can contribute to a consistent brand image across various communication channels, including customer support lines, advertisements, and promotional materials.
As technology continues to advance, the applications and benefits of speech synthesis in the business context are likely to expand further.
Challenges Associated With Speech Synthesis
- A synthesized voice may struggle to convey the nuanced emotions in a piece of text, making it sound monotonous or robotic rather than capturing the intended expressiveness.
- Synthesized voices often struggle with context awareness. Understanding and incorporating contextual cues, such as pauses, emphasis, and appropriate intonation based on the context of the conversation or text, is a complex challenge.
- Synthesizing uncommon words, technical terms, slang, short forms, and proper nouns not present in the training data can be challenging. Systems may mispronounce or struggle to generate these less common words accurately.

- Achieving real-time processing, especially in applications that require immediate responses (For example- virtual assistants), while maintaining high-quality output poses a challenge. Minimizing latency is helpful for a better user experience.
- Developing synthesis models that can accurately handle multiple languages and dialects is a challenge. Differences in phonetic patterns, intonation, and stress across languages and dialects require sophisticated modeling techniques.
Ethical Consideration Associated With Speech Synthesis
Ethical considerations in speech synthesis revolve around the responsible and fair use of this technology.

- Speech synthesis can be misused to create deepfake audio content; sometimes, video calls imitate real voices for malicious purposes such as spreading misinformation, impersonation, or generating fake endorsements.
- Collecting and using voice data for training synthetic voices raises privacy concerns. Users may be uncomfortable with their voices being used without explicit consent, especially if it can lead to realistic voice clones.
- If synthetic voices are used in security-critical applications like voice authentication, vulnerabilities in the synthesis process could be exploited for unauthorized access, leading to security risks.
- Speech synthesis models trained on biased datasets may perpetuate or amplify existing biases in terms of accent, gender, or language, leading to unfair and discriminatory outcomes.
- Using emotionally expressive synthetic voices in customer service or advertisements with the intent to manipulate or deceive consumers raises ethical concerns about emotional manipulation for commercial gain.
- Adherence to data protection regulations, such as GDPR, is crucial when collecting, storing, or processing voice data for training speech synthesis models.
- While speech synthesis can enhance accessibility, it’s essential to ensure that the technology is inclusive and caters to users with diverse linguistic backgrounds, accents, and speech patterns.
- High-quality voice synthesis can be used to impersonate individuals for identity theft or fraud, leading to potential legal and financial consequences for the impersonated person.
Addressing these ethical considerations involves adopting responsible practices in the development, deployment, and use of speech synthesis technology.
It requires transparency, user consent, efforts to mitigate biases, and adherence to privacy and security standards to ensure the ethical use of synthetic voices in various applications.
Final Words
We are in the future, and while flying cars may not be a reality yet, we can communicate with computers using natural languages and speech synthesis. Speech synthesis proves beneficial for content creators in generating content, businesses in automating daily voice-based repetitive tasks, and individuals as voice assistants.
In this article, we explored what speech synthesis is and how it works, discussed the various steps involved in speech synthesis, highlighted challenges, and considered ethical considerations.