Network protocol is a set of rules that devices use to communicate with each other over a network.
It’s similar to how people follow certain behaviors and procedures when talking to each other.
They specify things like how data packets should be structured, how devices should identify themselves, and how errors & conflicts should be handled.
Network protocols can be categorized into these three main types: Communication, Security, and Management.

#1. Communication Protocols
These protocols focus on enabling the exchange of data & information between devices on a network. They determine how data is formatted, transmitted, and received, which ensures effective communication. Examples are HTTP/HTTPS, FTP, TCP, and UDP.
#2. Security Protocols
Security protocols are designed to protect the confidentiality & authenticity of data as it traverses a network. They establish secure channels for communication and make sure that sensitive information is not vulnerable to interception or tampering.
Examples include SSL/TLS for encryption, SSH for secure remote access, and secure variants of email protocols like SMTPS and POP3S.
#3. Management Protocols
Management protocols are used for the administration, monitoring, and control of network devices/resources. They help network administrators configure and troubleshoot network components efficiently.
Some examples are DHCP for dynamic IP address allocation, SNMP for network device management, ICMP for diagnostic purposes, and BGP for routing & reachability information.
Let’s discuss some common protocols from each category.
Communication Protocols
HTTP
HTTP stands for Hypertext Transfer Protocol.
It is a fundamental protocol used for communication between a web browser and a server.
It is an application layer protocol that operates on top of the OSI model.
When you enter a URL in your web browser and press enter, it sends an HTTP request to a web server which then processes the request & sends back an HTTP response containing the requested information.
This could be a web page, an image, a video, or any other resource hosted on the server.

HTTP is a stateless protocol. It means each request from a client to a server is treated as an independent & isolated transaction.
The server does not maintain any information about previous requests from the same client. This simplicity is one of the reasons why HTTP is so widely used.
HTTP defines several request methods, including GET (retrieve data), POST (send data to be processed), PUT (update a resource), DELETE (remove a resource), and others. These methods determine the type of operation the client wants to perform on the server.
Generally, HTTP responses include a status code that indicates the outcome of the request.
For example – A status code of 200 indicates a successful request, while 404 indicates that the requested resource was not found.
And HTTP has seen several versions over the years, with HTTP/1.1 being one of the most widely used versions for a long time.
HTTP/2 and HTTP/3 (also known as QUIC) were developed to improve the performance.
HTTPS
HTTPS stands for Hypertext Transfer Protocol Secure.
It is an extension of the HTTP protocol used for secure communication over computer networks.
It adds a layer of security to standard HTTP by encrypting the data exchanged between a browser & web server using cryptographic protocols like SSL/TLS. Even if someone intercepts the data being transmitted, they cannot easily read or decipher it.
HTTPS includes a form of server authentication.
When a browser connects to a website over HTTPS, the website presents a digital certificate which is issued by a trusted Certificate Authority (CA).
This certificate verifies the identity of the website, which makes sure that the client is connecting to the intended server and not a malicious one.

Websites that use HTTPS are identified by “https://” at the beginning of their URLs. The use of this prefix indicates that the website is using a secure connection.
HTTPS generally uses port 443 for communication – whereas HTTP uses port 80. Web servers can easily differentiate between secure & non-secure connections using this distinction.
Search engines like Google prioritize websites that use HTTPS in their search rankings.
Browsers can also warn users when a secure HTTPS webpage contains elements ( images or scripts) served over an unsecured HTTP connection. This is known as “mixed content” and can compromise security.
Here is a detailed article on how to get an SSL Certificate for a Website. Feel free to visit this page.
FTP
File Transfer Protocol (FTP) is a standard network protocol used for transferring files between a client and a server on a computer network.
FTP operates on the client-server model. That means the client initiates a connection to another computer (the server) to request & transfer files.
FTP uses two ports for communication and can operate in two modes: Active mode and Passive mode.
Port 21 is used for the control connection where commands & responses are sent between the client and server.
Active mode is the traditional mode that works on the principle of the client-server model. An additional port (usually in the range of 1024-65535) is opened for data transfer here.
On the other hand, Passive mode is often used when the client is behind a firewall or NAT device and the server opens a random high-numbered port for data transfer.

FTP generally requires authentication to access files on the server. Users has to provide a username and password to log in.
Some FTP servers also support anonymous access. So, users can log in with a generic username like “anonymous” or “FTP” and use their email address as a password.
FTP supports two data transfer modes: ASCII mode & binary mode.
ASCII mode is used for text files and Binary mode is used for non-text files like images and executables. The mode is set based on the type of file being transferred.
Traditional FTP is not a secure protocol as it transmits data including usernames and passwords in plain text.
Secure FTP (SFTP) and FTP over SSL/TLS (FTPS) are more secure alternatives that encrypt the data transfer to protect sensitive information.
Here is a detailed article on SFTP vs FTPS and which protocol to use.
TCP
Transmission Control Protocol (TCP) is one of the main transport layer protocols in the IP suite.
It plays a major role in providing reliable and ordered data transmission between devices over IP networks.
TCP establishes a connection between the sender and receiver before any data transfer begins. This connection setup involves a three-way handshake (SYN, SYN-ACK, ACK) and a connection termination process when the data exchange is complete.
It also supports full-duplex communication that allows data to be sent and received simultaneously in both directions within the established connection.

Generally, TCP monitors network conditions & adjusts its transmission rate to avoid network congestion.
This protocol includes error-checking mechanisms to detect and correct data corruption during transmission. If a data segment is found to be corrupted, the receiver requests retransmission.
TCP uses port numbers to identify specific services or applications on a device. Port numbers help route incoming data to the correct application.
The receiver in a TCP connection sends acknowledgments (ACKs) to confirm the receipt of data segments. If the sender doesn’t receive an ACK within a certain time – it retransmits the data segment.
TCP maintains connection state information on both the sender and receiver sides. This information helps keep track of the sequence of data segments & manage the connection.
IP
IP stands for Internet Protocol.
It is a core protocol that enables communication & data exchange in computer networks, including the global network we know as the Internet.
IP uses a numerical addressing system to identify devices on a network. These numerical addresses are called IP addresses, and they can be either IPv4 or IPv6.
IPv4 addresses are typically in the form of four sets of decimal numbers (e.g., 192.168.1.1), while IPv6 addresses are longer and use hexadecimal notation.

IP routes the data packets between devices on different networks.
Routers & switches play a major role in directing these packets to their intended destinations based on their IP addresses.
Generally, IP uses a packet-switching methodology. That means data is broken into smaller packets for transmission across the network. Each packet contains a source and destination IP address that allows routers to make forwarding decisions.
IP is considered a connectionless protocol. It does not establish a dedicated connection between the sender & receiver before transmitting data.
Each packet is treated independently and can take different routes to reach its destination.
UDP
UDP stands for User Datagram Protocol.
It is a connectionless & lightweight protocol that provides a way to send data over a network without establishing a formal connection.
Unlike the TCP protocol, UDP does not establish a connection before sending data. It simply packages the data into datagrams and sends them to the destination.
It does not guarantee the delivery of data and it doesn’t implement mechanisms for error detection and correction. If a packet is lost or arrives out of order, it is up to the application layer to handle this.

UDP has less overhead than TCP because it doesn’t include features like flow control, error correction, or acknowledgments. This makes it faster but less reliable.
It also doesn’t have built-in congestion control mechanisms, so it’s possible to flood a network with UDP traffic which potentially causes congestion.
UDP is commonly used in situations where low latency and high-speed data transmission are more critical than guaranteed delivery. Some common examples are real-time audio and video streaming, online gaming, DNS, and some IoT applications.
The best thing about UDP is its multiplexing feature. It allows multiple applications on the same device to use the same UDP port which differentiates the data streams using port numbers.
let’s understand UDP with a simple example.
Imagine you want to send a message to your friend across a noisy playground using a bouncy ball. You decide to use UDP, which is like throwing the ball without any formal conversation. Here’s how it works:
- You write your message on a piece of paper and wrap it around the ball.
- You throw the ball in the direction of your friend. You don’t wait for your friend to catch it or acknowledge that they received it; you just throw it and hope they catch it.
- The ball bounces and reaches your friend, who tries to catch it. But sometimes, because of the noise it might bounce off their hands or arrive out of order.
- Your friend reads the message on the paper, and if they caught the ball successfully – they get the message. If not, they might miss it, and you won’t know because you didn’t have a way to check.
So, in this example:
The ball represents the UDP protocol which sends data without establishing a formal connection.
You sending the ball without waiting for a response is like UDP being connectionless and not ensuring delivery.
The possibility of the ball bouncing or getting lost symbolizes the lack of reliability in UDP.
Your friend reading the message is like the application layer handling the data received through UDP, which possibly deals with any missing data.
Security Protocols
SSH
SSH stands for Secure Shell. It is a network protocol used for secure communication between a client and a server over an unsecured network. It provides a way to remotely access & manage devices over a command-line interface with a high level of security.
SSH uses cryptographic techniques to authenticate both the client and the server. This makes sure that you are connecting to the correct server and that the server can verify your identity before allowing access.
All data transmitted over an SSH connection is encrypted, which makes it difficult for anyone intercepting the communication to eavesdrop on the data being exchanged.
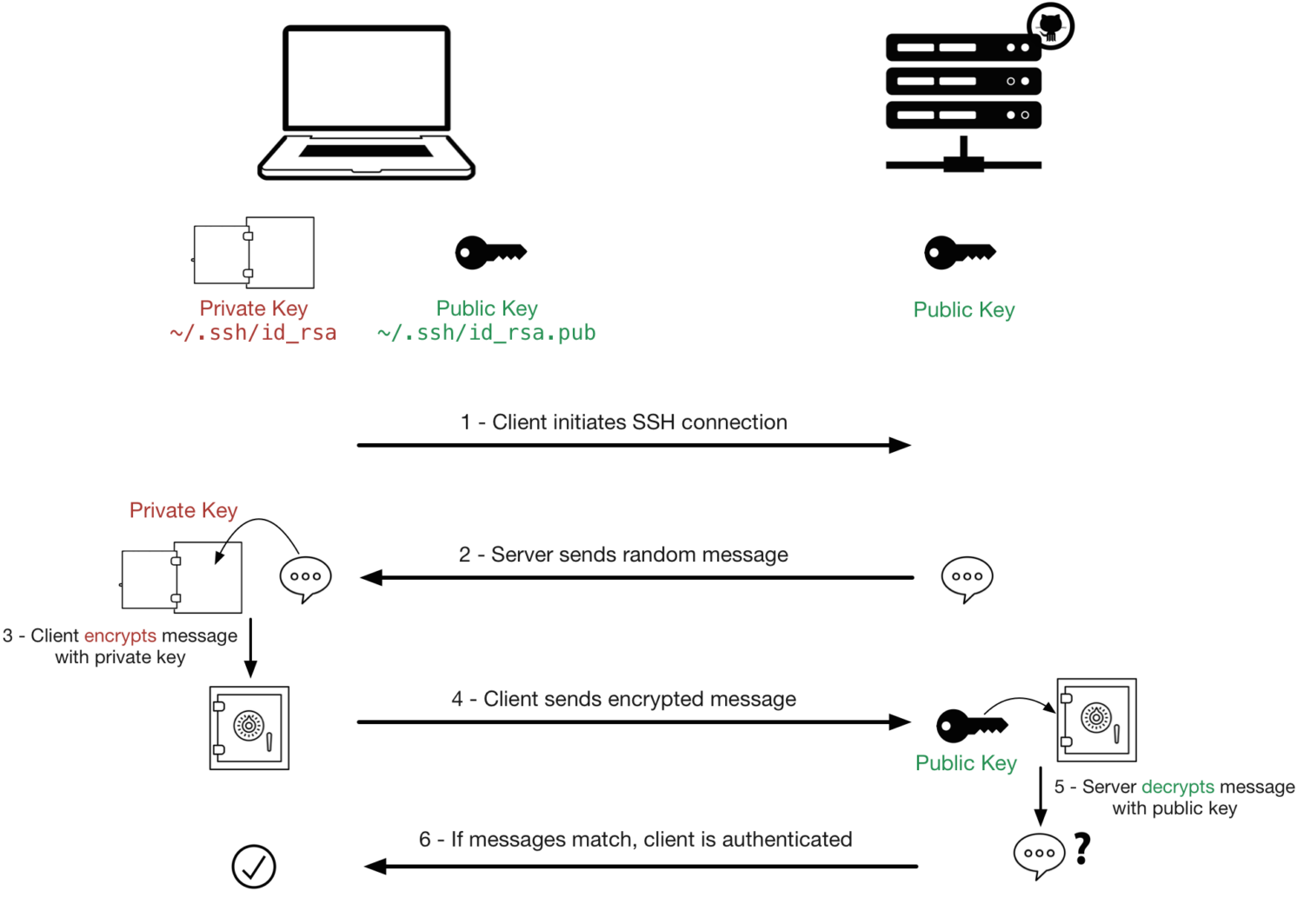
SSH uses a key pair for authentication. The key pair consists of a public key (which is shared with the server) and a private key (which you keep secret).
Here is an article on how it works – SSH Passwordless Login
When you connect to an SSH server, your client uses your private key to prove your identity.
Along with this, It also supports traditional username & password authentication. However, this is less secure and is often discouraged, especially for internet-facing servers.
SSH uses port 22 for communication by default – but this can be changed for security reasons. Changing the port number can help reduce automated attacks.
SSH is commonly used for remote server administration, file transfer (with tools like SCP and SFTP), and secure access to remote command-line interfaces.
It’s widely used in the administration of Unix-like operating systems and is also available on Windows through various software solutions.
SMTP
SMTP stands for Simple Mail Transfer Protocol.
It is a standard protocol responsible for sending outgoing email messages from a client or email server to an email server on the recipient’s end.
SMTP is a fundamental part of email communication, and it works in conjunction with other email protocols like IMAP/POP3 to enable the complete email lifecycle, including sending, receiving, and storing email messages.
When you compose an email and click “send” in your email client, it uses SMTP to relay the message to your email provider’s server.

It uses port 25 for unencrypted communication & port 587 for encrypted communication (using STARTTLS). Port 465 was also used for encrypted SMTP communication but is less common.
Many SMTP servers require authentication to send emails to prevent unauthorized use. Authentication methods like username and password or more secure methods like OAuth are used.
These SMTP servers are often used as relays, which means they accept outgoing emails from clients (e.g., your email app) and forward them to the recipient’s email server. This helps route emails across the Internet.
Communication can be secured using encryption via TLS or SSL – especially when sending sensitive or confidential information via email.
Management Protocols
POP3
POP3 stands for Post Office Protocol version 3.
It is one of the most common email retrieval protocols used for fetching email messages from a mail server to an email client application.
POP3 is designed to work in a “store-and-forward” manner. It retrieves emails from the server and then typically deletes them from the server after storing a copy on the client’s device.
Some email clients provide an option to leave a copy of the email on the server – but this is not the default behavior.
It uses port 110 for unencrypted communication. Port 995 is commonly used for secure POP3 communication using TLS/SSL.
POP3 is a stateless protocol. That means it does not keep track of the emails you’ve already downloaded. Each time you connect to the server, it retrieves all unread messages. This can lead to synchronization issues if you access your email from multiple devices.

POP3 is primarily designed to retrieve emails from the inbox. It may not support the retrieval of emails from other folders on the server, such as sent items or drafts.
Since POP3 doesn’t synchronize email folders between the server and the client – Actions taken on one device (e.g., deleting an email) won’t be reflected on other devices.
It’s recommended to use the secure version of POP3 (POP3S or POP3 over SSL/TLS), which encrypts the communication between the email client and server to improve security.
POP3 is less commonly used today compared to IMAP (Internet Message Access Protocol). It provides more advanced features like folder synchronization & allows multiple devices to manage the same mailbox more effectively.
BGP
BGP stands for Border Gateway Protocol.
It is a standardized exterior gateway protocol used in networking to exchange routing & reachability information between autonomous systems (ASes).
An autonomous system is a collection of IP networks and routers under the control of a single organization that presents a common routing policy to the Internet.
BGP is a path vector protocol. That means it keeps track of the path (list of autonomous systems) that data packets take to reach their destination. This information helps BGP routers make routing decisions based on policies & path attributes.

It’s primarily used to determine the best path for data to traverse when crossing multiple networks operated by different organizations or ISPs.
Also supports route aggregation that helps reduce the size of the global routing table by summarizing multiple IP prefixes into a single route announcement.
BGP protocol uses various mechanisms to prevent routing loops, including the use of the AS path attribute & the split-horizon rule.
It is used in both the public internet and private networks.
In the public internet, it’s used to exchange routing information between ISPs and large networks. In private networks, it’s used for internal routing and connecting to the internet through a border router.
DHCP
DHCP stands for Dynamic Host Configuration Protocol.
It is used to automatically assign IP addresses & other network configuration settings to devices on a TCP/IP network.
The DHCP process generally involves four main stages:
DHCP Discover
When a device joins a network – it sends out a DHCP Discover broadcast message to find available DHCP servers.
DHCP Offer
DHCP servers on the network respond to the DHCP Discover message with a DHCP Offer. Each server provides an IP address and related configuration options.
DHCP Request
The device selects one of the DHCP Offers & sends a DHCP Request message to the chosen server that requests the offered IP address.
DHCP Acknowledge
The DHCP server acknowledges the request by sending a DHCP Acknowledgment message that confirms the IP address assignment.

Let’s understand the DHCP working principle with a simple example.
Imagine you have a home Wi-Fi network and you want your devices (like phones and laptops) to connect to it without manually setting up each device’s network settings. That’s where DHCP comes in:
- Let’s say your smartphone just joined your home Wi-Fi network.
- The smartphone sends out a message saying, “Hey, I’m new here. Can someone give me an IP address and other network details?”
- Your Wi-Fi router acting as a DHCP server hears the request. It says, “Sure, I have an available IP address, and here are the other network settings you need – like the subnet mask, default gateway, and DNS server.”
- The smartphone receives this information and automatically sets itself up with the provided IP address & network settings.
Smartphone is now ready to use the internet and communicate with other devices on your home network.
ICMP
Internet Control Message Protocol (ICMP) is a network layer protocol that is used in the IP suite to enable communication & provide feedback about the status of network operations.
ICMP is mainly used for reporting errors and providing diagnostic information related to IP packet processing.
For example, if a router encounters a problem while forwarding an IP packet – it generates an ICMP error message and sends it back to the source of the packet.
Common ICMP error messages include “Destination Unreachable,” “Time Exceeded,” and “Parameter Problem.”
One of the most well-known uses of ICMP is the “ping” command (used to check the reachability of a host).
This ping command sends ICMP Echo Request messages to a destination host, and if the host is reachable, it should respond with an ICMP Echo Reply message. This is a simple way to test network connectivity.

ICMP is also used for Path Maximum Transmission Unit (PMTU) discovery. PMTU is the maximum size of an IP packet that can be transmitted without fragmentation along a path.
ICMP messages such as “Fragmentation Needed” and “Packet Too Big” are used to determine the appropriate MTU for a given path which helps to avoid fragmentation and optimize data transfer.
Also, These messages can be used to track the time it takes for packets to travel from the source to the destination and back. The “Time Exceeded” message is used for this purpose.
SNMP
SNMP stands for Simple Network Management Protocol.
It is an application layer protocol for managing and monitoring network devices/systems.
SNMP operates using a manager-agent model. There are two main components.
SNMP Manager
The manager is responsible for making requests and collecting information from SNMP agents. It can also set configuration parameters on agents.
SNMP Agent
The agent is a software module or process running on network devices. It stores information about the device’s configuration & performance. The agent responds to requests from SNMP managers.
MIB (Management Information Base) is a hierarchical database that defines the structure and organization of managed objects on a network device. It serves as a reference for both SNMP managers and agents, which makes sure that they understand each other’s data.

There are three versions of SNMP that are being used widely.
SNMPv1: The original version of SNMP that uses community strings for authentication. It lacks security features and is considered less secure.
SNMPv2c: An improvement over SNMPv1 with support for additional data types & improved error handling.
SNMPv3: The most secure version of SNMP, which offers encryption, authentication, and access control. It addresses many of the security concerns of earlier versions.
SNMP is used for various network management tasks such as monitoring bandwidth utilization, tracking device uptime, configuring network devices remotely, and receiving alerts when specific events occur (e.g., system failures or threshold breaches).
Conclusion✍️
I hope you found this article very useful in learning about the various network protocols. You may also be interested in learning about network segmentation and how to implement it.