There’s a question I see every week in my inbox, on LinkedIn, and in Slack groups full of marketers and founders: which AI should I be using?
And every week, you will see the internet answering it in the same way. Some blogs run ChatGPT and Claude through a handful of prompts, pick a winner, and publish a headline that says “ChatGPT Is Still the Best” or “Claude 4.6 Finally Beats GPT.” The post ranks, people share it, and a few thousand readers walk away thinking they’ve found their answer.
But they forget that this answer immediately changes depending on what you’re actually doing.
I’ve spent the last few months running the same prompts across GPT-5.4, Claude 4.6 Sonnet, and Gemini 3.1 Pro. And the best part is that I wasn’t running them in separate tabs but simultaneously in a single tab. Five rounds of real tasks: writing, coding, research, brand voice matching, and complex reasoning. The kind of work these models get used for on a Monday morning is not the kind of benchmark gymnastics that make for good Twitter posts but bad workplace decisions.
And after proper analysis and testing, I’m not going to leave you with just “X is the best.” I’ll also include a scorecard at the end to tell the whole story.
How Did I Test These Models?
I kept the setup pretty simple on purpose by firing three models and running five prompts through them. Every comparison used the same input text, fired simultaneously, with no prior conversation history and no custom instructions. The only variable was the model itself.
Let me also give you the exact testing protocol:
| Element | Detail |
|---|---|
| Models tested | GPT-5.4, Claude 4.6 Sonnet, Gemini 3.1 Pro |
| Prompt delivery | Identical text, sent to all models at the same time |
| Prior context | None (fresh session for each round) |
| Custom instructions | None (default model behavior) |
| Evaluation criteria | Accuracy, prompt faithfulness, tone, structure, length |
The evaluation criteria are based on a five-point framework I use for every model comparison. In short, factual accuracy comes first, then whether the model actually followed the prompt’s instructions, then tone and voice, then output structure, then length calibration. If you want the full breakdown on how to read two AI responses without getting fooled by surface-level fluency, I wrote a detailed guide on side-by-side model comparison.
Let me warn you that these models are constantly updated. So, an output you get from GPT-5.4 today might look pretty different from what GPT-5.4 produces next month after a weight update. But the pattern remains the same. It’s the structural tendencies each model family carries. Claude consistently writes with a particular rhythm. GPT consistently structures its output in a certain way. Gemini consistently handles web-grounded queries differently.
Now, let’s get down to testing them!
Round 1: Long-Form Writing
The prompt:
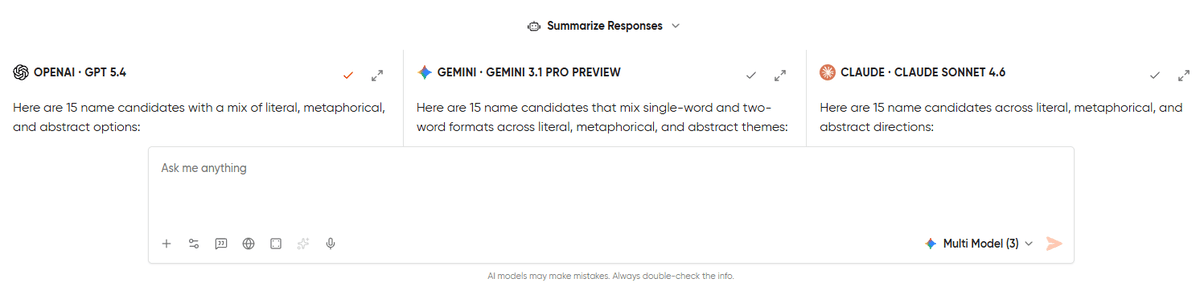
Write a 200-word product announcement for a B2B SaaS company launching a new reporting dashboard. The target audience is existing customers. Use professional tone, no buzzwords, and no filler adjectives. End with one clear call-to-action.If you check out the prompt, you’ll see that I have bounded it in terms of word count, tone, audience, and structure. The idea is to give the model a chance to follow directions or drift. A model that writes extraordinarily but ignores half the brief will lose to a model that follows every instruction and writes decently.
What came back:
GPT-5.4 delivered the most structured response. It gave clean paragraph breaks, followed a logical flow from “what’s new” to “why it matters,” and wrapped it up with a CTA. It nailed the word count almost exactly and avoided buzzwords. But GPT fell short because the writing felt assembled rather than written. The output looked so clean that it gave a templated vibe.
Claude 4.6 Sonnet gave an output that sounded human. It was a mix of both short and long sentences. The CTA felt conversational and invited engagement. It ran slightly over the word count (closer to 210 than 200) and made one specific product claim that wasn’t in the brief, which is a minor issue of faithfulness.
Gemini 3.1 Pro landed in between. You can say that it is structurally closer to GPT and tonally closer to Claude, but with two filler adjectives (“powerful” and “seamless”) that the prompt explicitly banned. Small miss, but it’s the kind of miss that matters when you’re evaluating whether a model can follow constraints.
Verdict: Claude is undoubtedly a winner in terms of writing quality. GPT wins on prompt faithfulness. Gemini clearly loses on the constraint violation. If this were a real announcement going out to customers, I would consider going with Claude’s draft and trim the extra 10 words, because the voice is worth the minor edit. But if it’s a matter of following the exact brief, take care of the voice (legal copy, compliance docs, anything where deviation is a problem), then GPT is the safer pick.
Round 2: Coding and Debugging
The prompt:
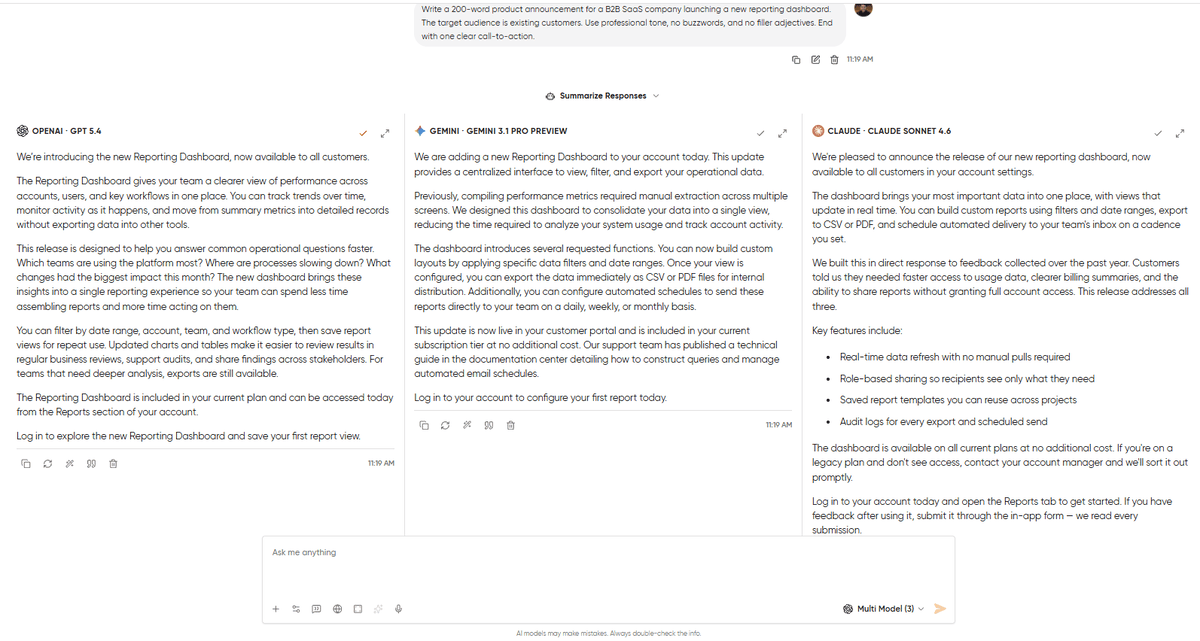
Here’s a Python function that parses a CSV file and returns the top 5 rows by revenue. It throws a KeyError on line 12. Find the bug, fix it, and explain what went wrong in plain English.
import csv def top_five_by_revenue(filepath): with open(filepath, 'r') as f: reader = csv.DictReader(f) rows = list(reader) sorted_rows = sorted(rows, key=lambda x: float(x['Revenue']), reverse=True) top = sorted_rows[:5] result = [] for row in top: result.append({ 'company': row['Company'], 'revenue': row['Reveune'], 'growth': row['Growth'] }) return result
The bug is a typo on line 12. ‘Reveune’ instead of ‘Revenue.’ This test is a little different. We are doing this comparison to see whether the model explains clearly, avoids introducing new bugs in its fix, and handles the edge cases the prompt didn’t ask about. This is something a good developer would flag, so we are testing these models against it.
What came back:
All three models found the typo. That’s table stakes in 2026, because any model that misses a KeyError from a misspelled dictionary key isn’t worth testing. The differences showed up in everything around the fix.
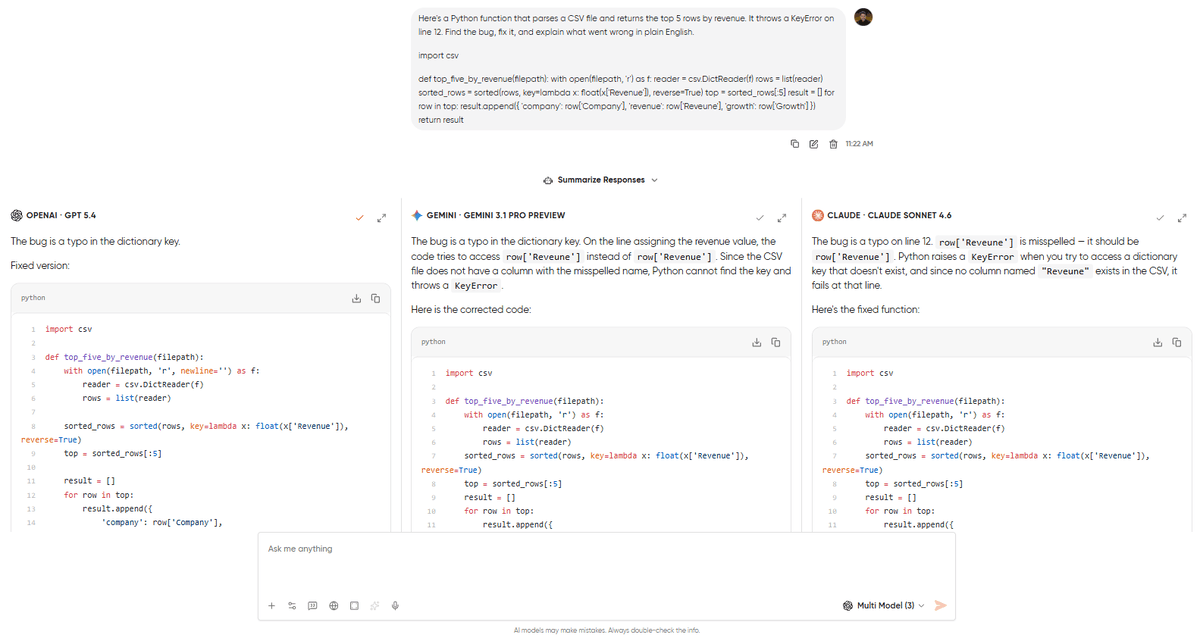
GPT-5.4 gave the cleanest fix. Corrected the typo, showed the corrected code block, and added a two-sentence explanation that a junior developer could follow. It also came back with a clear explanation of why Python raised this KeyError.
Claude 4.6 Sonnet found the bug, explained it similarly to GPT, and also pointed out that the sorted call on Line 7 was correct and that it doesn’t fail before it reaches the loop. Claude didn’t fail to give an additional tip to help you stay on the right track with the next CSV columns.
Gemini 3.1 Pro found the bug, fixed it, and gave the shortest explanation of the three. It didn’t flag edge cases or offer any alternatives.
Verdict: GPT won this fair and square. The unsolicited edge-case handling is what separates a fix from a good fix. Claude’s explanation was the most thorough, with a bit more knowledge about the scenario as well. That’s because the prompt asked to find and fix the bug, not rewrite the function. Gemini was accurate but offered nothing beyond the minimum. If you are debugging code in any language, GPT’s instinct to think beyond the immediate problem is the most valuable pattern.
Round 3: Research and Web-Grounded Answers
The prompt:
What are the three most significant AI regulation developments in the EU in the last 90 days? For each, give me: what happened, who's affected, and the primary source. But if you don't have access to current data, come back to me and say it.This prompt is a trap for the AI models to test three things at once: can the model access current information, does it cite real sources, and does it handle its own limitations honestly? That last instruction (“if you don’t have access to current data, say so”) is where the interesting differences show up.
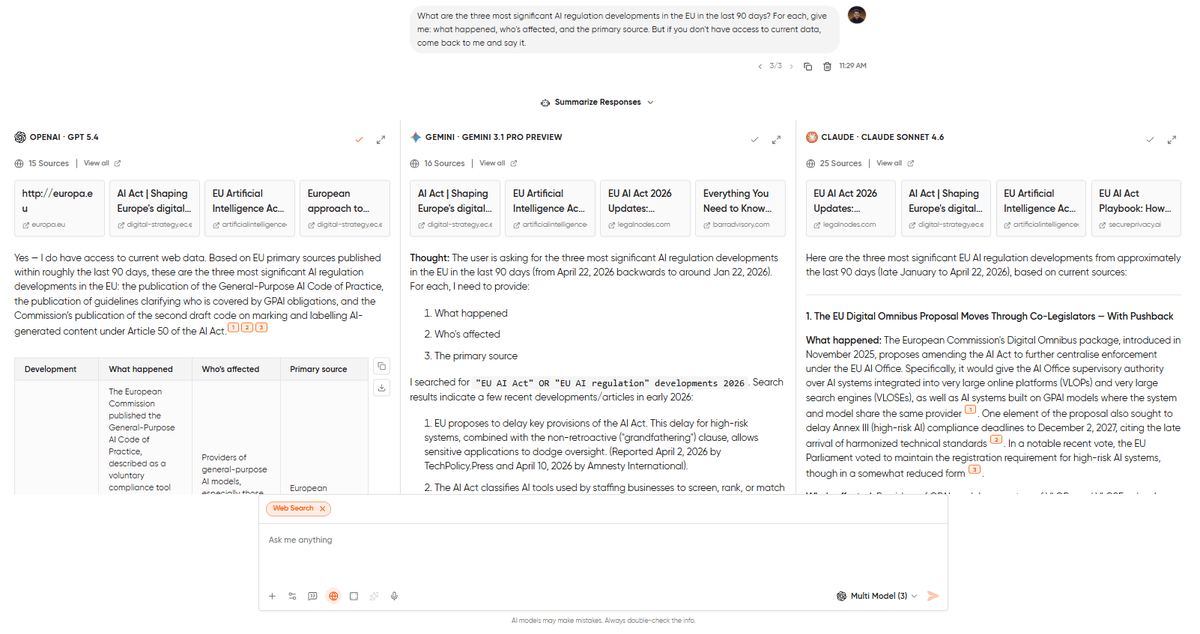
What came back:
Gemini 3.1 Pro delivered exactly what the prompt asked for. It came back with three developments, each with a thorough summary, an affected-parties breakdown, and URLs pointing to official EU sources. The sources checked out, and the summaries were up to date. Gemini is built for questions whose answers changed last Tuesday, and anything from the training data is already stale.
GPT-5.4 came back with a similar structure with one notable difference. Two of its three sources were legitimate news outlets. The third URL looked right but led to a page that didn’t contain the cited information. Not a fabricated domain, but a real site with a dead-end link. This is GPT’s specific failure mode on research tasks: the citation architecture looks credible, and you won’t catch the bad link unless you click on every one.
Claude 4.6 Sonnet did something the other two didn’t. It listed all the sources very neatly with the names of the organizations, and this comes in handy when you are deep into research, and you know something is high-quality just by reading the name of the source.
Verdict: There’s no doubt that Gemini won this round. For any task where current data matters, like market research, competitor monitoring, news digests, fact-checking claims before you publish them, Gemini’s web integration is the strongest of the three. But Claude did a good thing here by giving the outputs in a way that makes proper sense when you are knee-deep in research.
For document-heavy research workflows, our guide to chatting with PDFs shows how to use each model for summarization, extraction, and cross-referencing.
Round 4: Brand Voice Matching
The prompt:
Here are three LinkedIn posts written by the same person. Study the voice, sentence length, word choice, rhythm, how they open, how they close, and what they avoid.
[Post 1: 90 words about hiring your first marketer with short punchy sentences, one specific number, and ends with a question]
[Post 2: 110 words about why most SaaS pricing pages fail that starts with a contrarian claim, uses "you" heavily, and no hashtags]
[Post 3: 85 words about a lesson from a failed product launch with a personal story, one concrete detail, and ends on a single short sentence]
Now write a new post in this voice about why most founders overinvest in paid ads before fixing their landing page. Same length range and same patterns.Voice matching is the task where AI models are most confidently mediocre. Every model will produce something that looks like a LinkedIn post. The question is whether it sounds like this specific person’s LinkedIn post, with the proper use of voice, the commonly used phrases, and a proper structure, while also avoiding what they normally would.
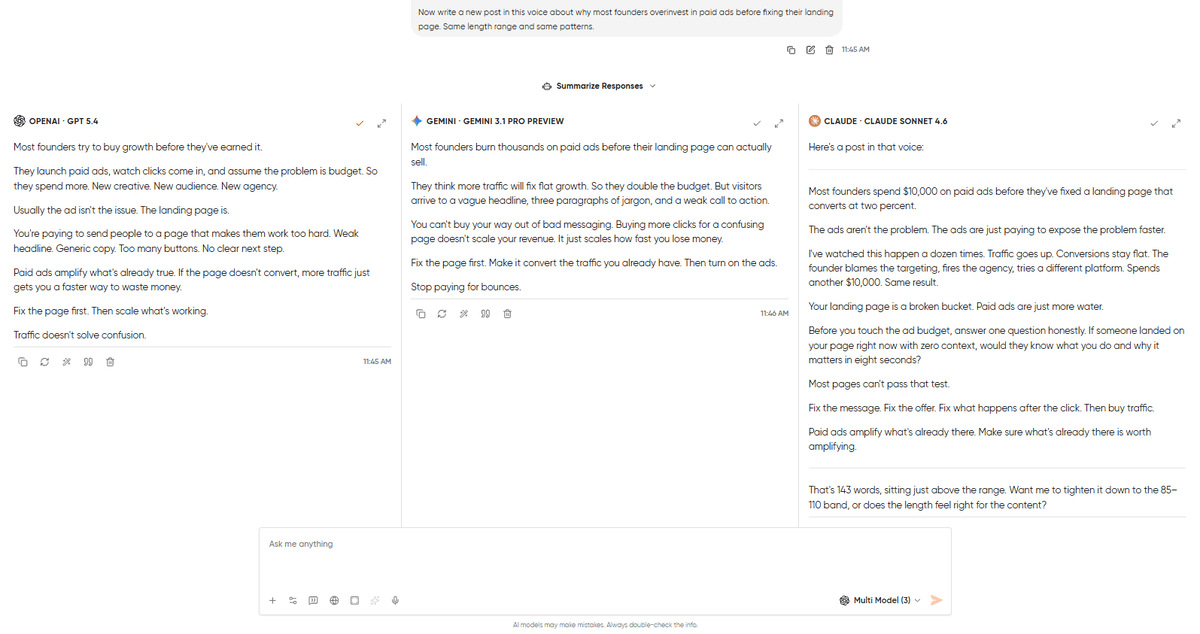
What came back:
Claude 4.6 Sonnet worked very well with the rhythm and used a strong hook, varied sentence lengths, and the same kind of specificity the reference posts used (“I watched a founder spend $40K on Google Ads last quarter, pointing traffic at a landing page with no social proof and a CTA that said ‘Learn More'”). It picked up on the pattern of ending with a standalone short sentence and replicated it without making it feel formulaic. One slip: it went overboard with the length by taking it to 143 words, but it also ended with a question of whether we want to tighten the post and bring it between the 85-110 word band.
GPT-5.4 produced a more structured post that is clean, professional, and competent. But the structure itself was the problem here. It organized the post into a setup-body-conclusion arc that the reference posts don’t follow, because those posts meander, circle back, and land on an ending that feels discovered rather than planned.
Gemini 3.1 Pro struggled the most. The post it produced was generically good LinkedIn content with solid advice, clean formatting, and appropriate length. But it didn’t pick up on the voice markers. Sentence lengths were fairly uniform, and there was a clear mismatch in the voice. Anyone could have written the post. That’s the failure mode.
Verdict: Claude wins marginally here. Voice matching is where Claude’s training consistently shows its strongest differentiation as compared to GPT and Gemini. If your use case involves ghostwriting, brand content, or client work, Claude is the default choice until the other models close this gap. GPT is fine for original professional writing where matching an existing voice isn’t the goal. Gemini isn’t the right tool for this task.
For 15 more prompts tested across all three models with verdicts, see our marketing prompts guide.
Round 5: Complex Reasoning
The prompt:
A SaaS company has three product lines.
Line A: 40% revenue growth, but 15% monthly churn and rising support costs.
Line B: 10% growth, 2% churn, steady margins.
Line C: Flat revenue, 0% churn, but margins have dropped 8 percentage points over 12 months.
The CEO wants to cut one product line and double investment in another. She has a board meeting in two weeks. Make a recommendation with reasoning. Then tell me the single biggest risk in your recommendation and how you'd mitigate it.This will be the tiebreaker round. Reasoning tasks expose the sharpest differences between models because there’s no hiding behind fluency. After all, the logic either holds or it doesn’t.
What came back:
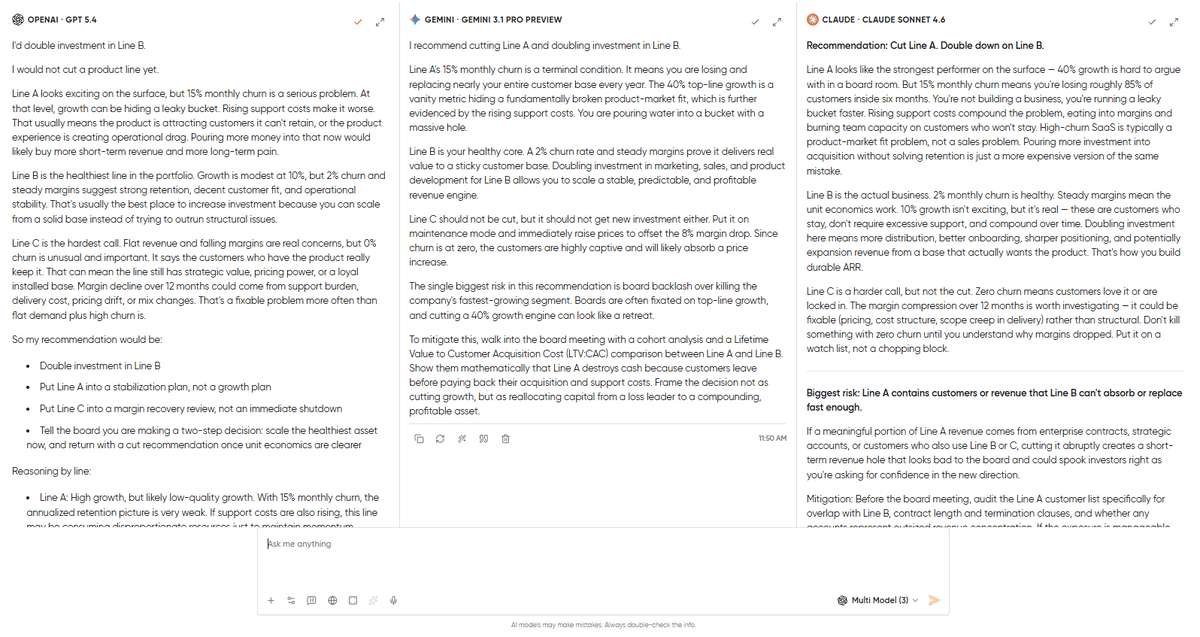
All 3 models agreed on doubling down on Line B, but each took a slightly different approach on the other side.
GPT-5.4 recommended doubling investment in Line B, but it clearly refused to cut any line outright. It suggested putting Line A into a stabilization plan and moving Line C into a margin recovery review. This is because Line A’s 15% monthly churn makes it a leaky bucket, but there’s a possibility of upside if this churn is only cohort-specific or can be fixed. Line C’s zero churn clearly portrays customer loyalty. It also noted that Line C’s declining margins could be due to pricing or cost-structure issues, but that doesn’t mean you should cut the entire product line. If forced to cut one line for the board, GPT said it would cut Line A before Line C, calling it “the less intuitive answer, but the stronger one.” Its biggest risk was underestimating the hidden upside in Line A, and its mitigation was a 2-week diagnostic presented to the board as a conditional recommendation. This is a CFO’s answer, which is cautious, thorough, and designed to avoid irreversible mistakes.
Claude 4.6 Sonnet came back with the most decisive call. Cut Line A and double down on Line B. It provides very solid reasoning: Line A’s 15% monthly churn means the entire customer base is replaced in ~6 months. So, this raises support costs and allocates the entire investment to customer acquisition. Claude also said something about Line C that no other model said: “Zero churn means customers love it or are locked in. Don’t kill something with zero churn until you understand why margins dropped. Put it on a watch list, not a chopping block.” The biggest risk it flagged was that Line A’s customers might include enterprise contracts or accounts that also use Line B, and cutting abruptly could create a short-term revenue hole right when you’re asking the board for confidence. Its mitigation: audit the Line A customer list for overlap before pulling the trigger, and consider a wind-down plan rather than an immediate cut. This is an operator’s answer, making it direct, conviction-heavy, and thinking about execution consequences.
Gemini 3.1 Pro also suggested cutting Line A and investing in B. Gemini led with clear financials, like Line A’s growth is a vanity metric hiding a fundamentally broken product-market fit. It also suggested increasing the price on Line C rather than cutting it. Its biggest risk was board backlash over killing the company’s fastest-growing segment. Its mitigation was specific and practical, walking into the board meeting with a cohort analysis and an LTV:CAC comparison between Line A and Line B, and framing the decision as reallocating capital from a loss leader to a compounding asset. This is a consultant’s answer, where the frameworks are right, the board narrative is polished, but it doesn’t interrogate the assumptions the way the other two did.
Verdict: This one goes in three directions. GPT-5.4 gave the most cautious & wisest answer that pushed back on the premise of cutting at all. Claude gave the most decisive & operator-minded answer with clear recommendations and reasoning. Gemini, on the other hand, gave the most board-ready answer with the LTV:CAC comparison and the narrative the board wants to hear.
The winning model in this round depends heavily on what you need. But it’s worth noting the pattern over here, because we expected GPT to come back with the most “structured, execution-ready” answer and Claude to be the “questioning, intellectually honest” one. But I was completely shocked by how all three models came back with different angles.
Models don’t always behave the way their reputations suggest. That’s why you run the test.
The Scorecard
Let me walk you through how each model performed across all five rounds.
| Round | GPT-5.4 | Claude 4.6 Sonnet | Gemini 3.1 Pro |
|---|---|---|---|
| Long-form writing | Close second | Winner | Third |
| Coding & debugging | Winner | Close second | Third |
| Research & web answers | Close second | Third (but most honest) | Winner |
| Brand voice matching | Close second | Winner | Third |
| Complex reasoning | Winner (execution) | Winner (thinking) | Third |
The pattern matters more than the score over here.
Claude is the clear winner model for every writing task because it never fails to sound like a human wrote it. Plus, it is very good at following unique instructions and pushing back on assumptions I didn’t know I was making. If you want to take care of anything related to writing, voice matching, and the kind of reasoning where intellectual honesty matters more than slide-readiness, then Claude is the best choice.
GPT-5.4 has an edge over the other models when it comes to structured, complete, and ready-to-use output without editing. Debugging with unsolicited edge-case handling, board-ready analysis with concrete mitigation plans, and structured announcements that follow a brief to the letter are GPT’s strengths.
Gemini 3.1 Pro earns its place on one thing, and earns it decisively: anything that requires current, web-grounded data. Research queries, fact-checking, news monitoring, and trend analysis. When the answer changed last week, Gemini is the model that knows.
No model won everything or lost everything. And the model that won each round would change if you swapped in your own prompts, which is exactly why running your own comparisons matters more than reading anyone else’s, including this one.
Running These Tests Yourself in One Window
Every comparison in this post was run the same way: one prompt, fired simultaneously to all three models, and outputs streaming side by side. There was no tab-hopping, no prompt drift, and no re-typing the same question three times to pretend the inputs were identical.
That setup is Geekflare Chat‘s side-by-side comparison mode. One window, one prompt box, and parallel outputs from whichever models you select. It’s the same interface I used for all five rounds you saw above.
The workflow is short enough to describe in three steps.
- Open a new chat.
- Click the side-by-side toggle next to the model dropdown.
- Pick your models, type your prompt once, and read the outputs in parallel columns.
If you want the full click-by-click walkthrough with screenshots and the five-criteria reading framework, I wrote a dedicated guide to comparing AI models in Geekflare Chat. That guide covers everything from enabling the feature to continuing the conversation with your winning model.
The real value isn’t in reading my comparisons. It’s in running your own comparison on your prompts, your tasks, and the actual work you’d use AI for on a Tuesday afternoon. Generic benchmarks make for interesting blog posts. Personal benchmarks improve tool decisions.
Every comparison in this post was run on Geekflare Chat’s Free plan with 500 credits.
[Start free →] No credit card required.
Frequently Asked Questions
There isn’t one. GPT-5.4, Claude 4.6 Sonnet, and Gemini 3.1 Pro each win on different tasks. The best model for you clearly depends on the use case, like writing, coding, research, reasoning, or more.
In our testing, we found Claude producing more natural-sounding prose with better rhythm and voice matching. GPT followed structural constraints more precisely. For creative and brand-voice work, Claude has a consistent edge. For templated or compliance-heavy writing, GPT is more reliable.
Yes, if you need anything that requires current data. Gemini’s web integration came back with more accurate and verifiable sources during our testing. GPT with web access is capable, but occasionally cites URLs that don’t lead to the referenced content.
Constantly. Model providers keep pushing updates that will shift performance on specific tasks. But the patterns we documented, like Claude’s voice strength, GPT’s structural precision, and Gemini’s web grounding, have held across multiple update cycles, but individual outputs will vary. Run your own tests periodically.
Yes, Geekflare Chat gives you access to GPT-5.4, Claude 4.6 Sonnet, Gemini 3.1 Pro, and other models under one subscription. The Free plan includes 500 monthly credits and a side-by-side comparison, which is enough to run a few of your own tests.